排查经历
问题现状
问题现状是,保存作品,发放奖品,偶现500错误,请求超时,查看日志,错误日志如下。
查看日志
org.springframework.transaction.CannotCreateTransactionException: Could not open JDBC Connection for transaction; nested exception is java.sql.SQLException
at org.springframework.jdbc.datasource.DataSourceTransactionManager.doBegin(DataSourceTransactionManager.java:287) ~[spring-jdbc-4.3.29.RELEASE.jar!/:4.3.29.RELEASE]
at org.springframework.transaction.support.AbstractPlatformTransactionManager.getTransaction(AbstractPlatformTransactionManager.java:377) ~[spring-tx-4.3.29.RELEASE.jar!/:4.3.29.RELEASE]
at org.springframework.transaction.interceptor.TransactionAspectSupport.createTransactionIfNecessary(TransactionAspectSupport.java:464) ~[spring-tx-
这类问题,其实归根就是猜,带着思路和线索去猜,这类问题一般可能由多种原因联合引发,有同学说看源码,看源码可以协助,但是不能对它报太多期望,因为通常很多人只能胜任一道俩门语言,如果出现一个问题,跨多端引发,这时候就无法通过阅读源码去发现。
由于它是偶现,通常很多次之后保存作品,发放奖品,触发之后偶现几次,这俩个操作的共同特性是用到的事务比较多,事务比较大,可能一次请求耗费了多个事务。一个事务对应一个连接。
第一个猜测
由于我们mps的连接池配置最大为50,如果定时任务中的出现大事务,定时任务的执行频次较高,比如一个定时任务执行需要耗费2分钟,但是该定时任务5秒触发一次,每次开启一个大事务,这种情况,单纯的定时任务就会把连接池耗光,影响其他请求。
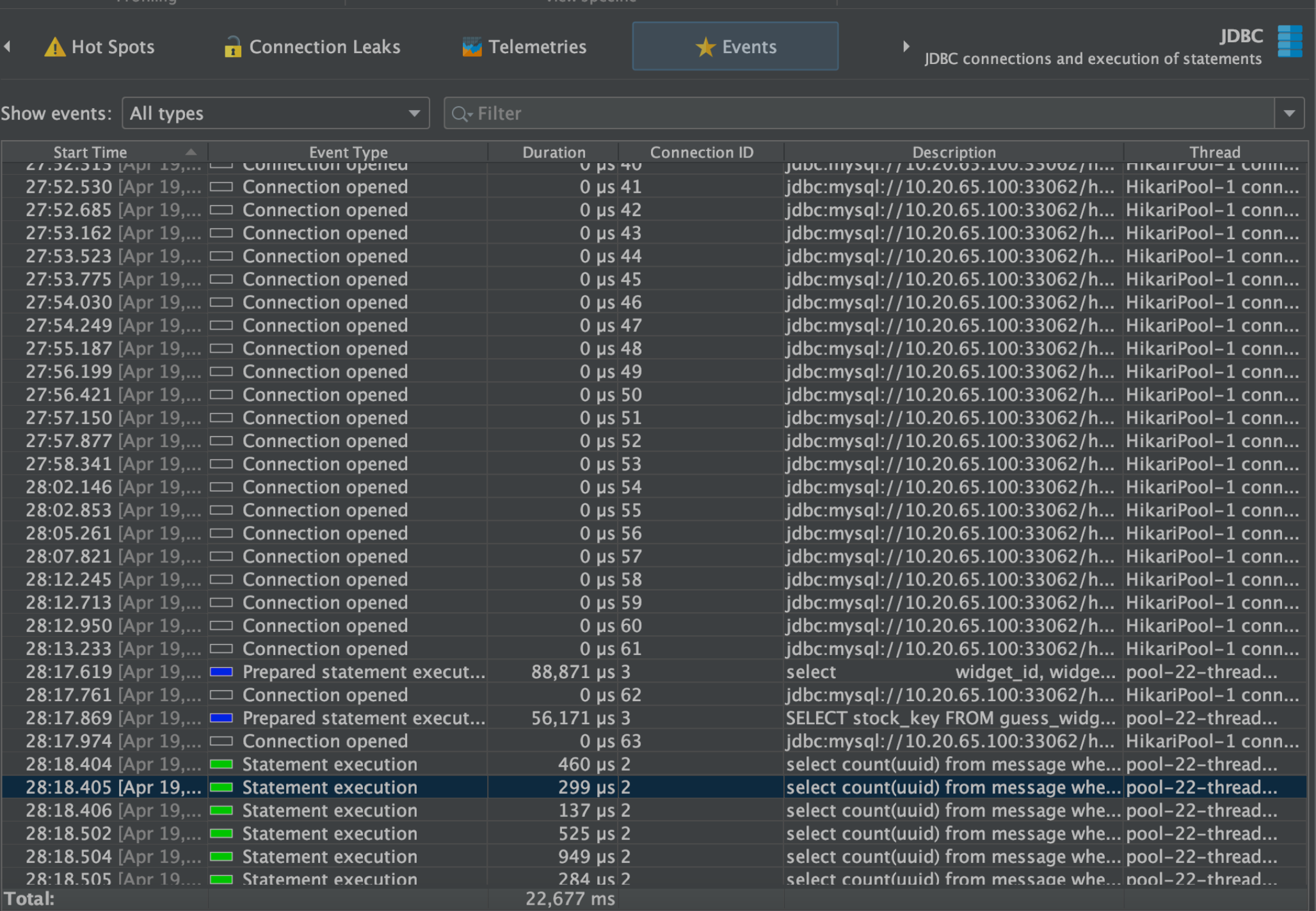
经过检查代码,发现代码里有定时任务加事务的情况。修复了之后,仍然会有这种情况,但是情况缓解了不少,经过阅读源码,hikariPool连接池,即便没有使用场景也会有连接池保持功能,会隔一段时间释放未被使用连接,再重新申请一批连接。
第二个猜测
此时还没有找到核心问题,还是时不时的会出现CannotCreateTransactionException问题,这问题,应该是从mysql那一层抛出来的,我想到了我们的一个线上问题,数据库被打爆的情况,其他应用也受影响了,那会不会是mysql被其他应用搞满载了,然后影响到了我们当前微服务,
证实了我的猜测
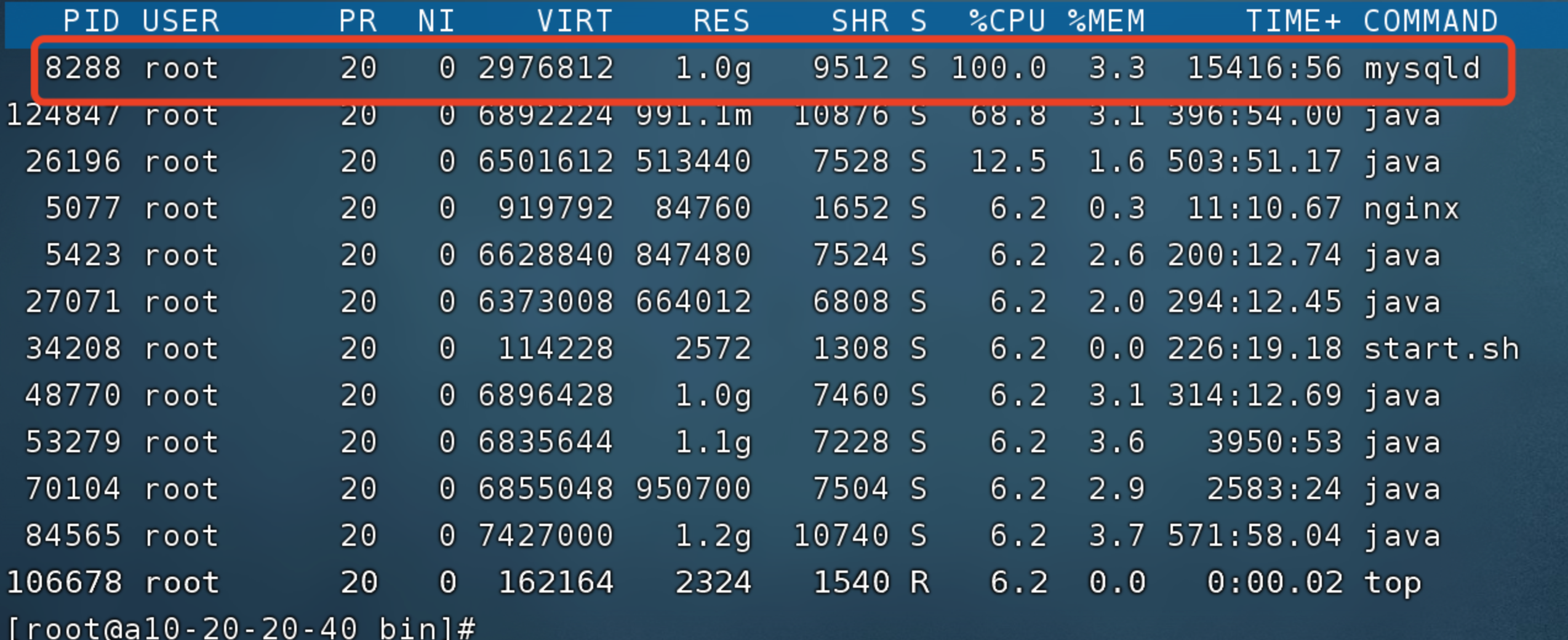
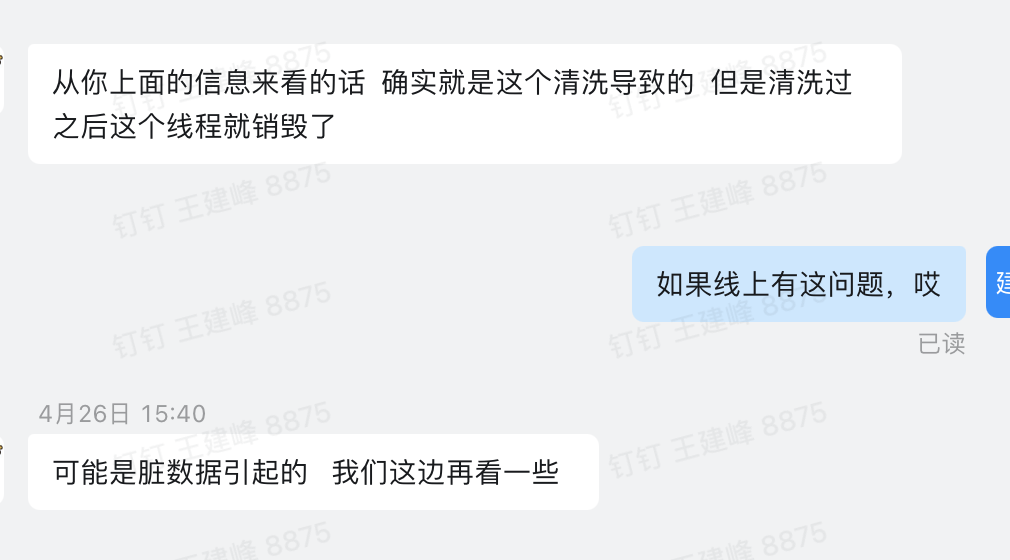
mysql一直处于满载的状态,检查具体线程

page_cleaner_thread 线程导致的,这个线程是mysql专门用来刷脏页的线程,这个线程负载过高,一般情况是,update,insert,select交互频次过高,https://www.modb.pro/db/176619
一个数据刚被写入,立马就需要被读取。
这时候逐个排斥连接该mysql的java应用,排查到某个项目时,jprofiler以下异常
ygc的频次很高,然后定时任务update频次过高。
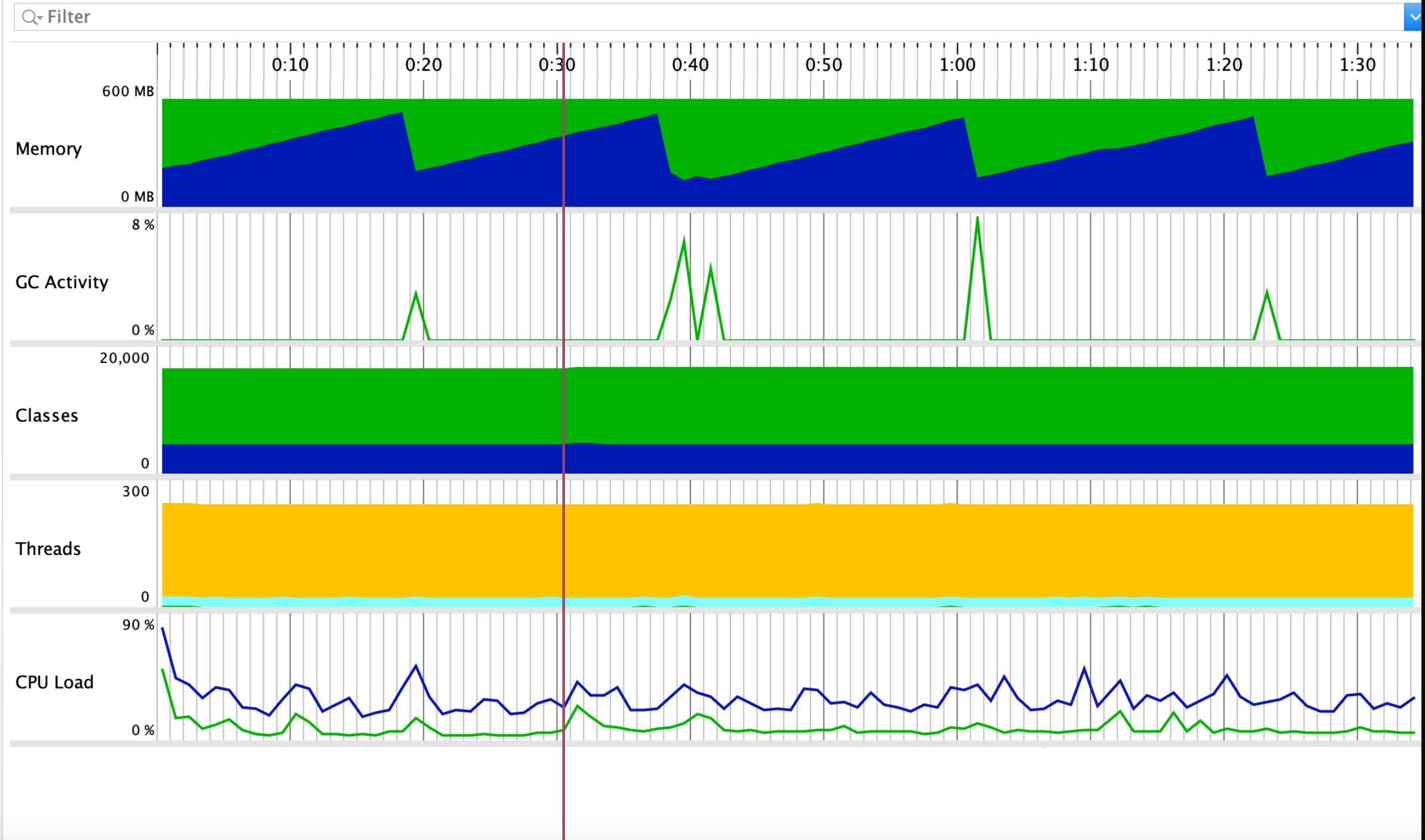

update每秒操作数据接近1000次 ,触发入口定位,
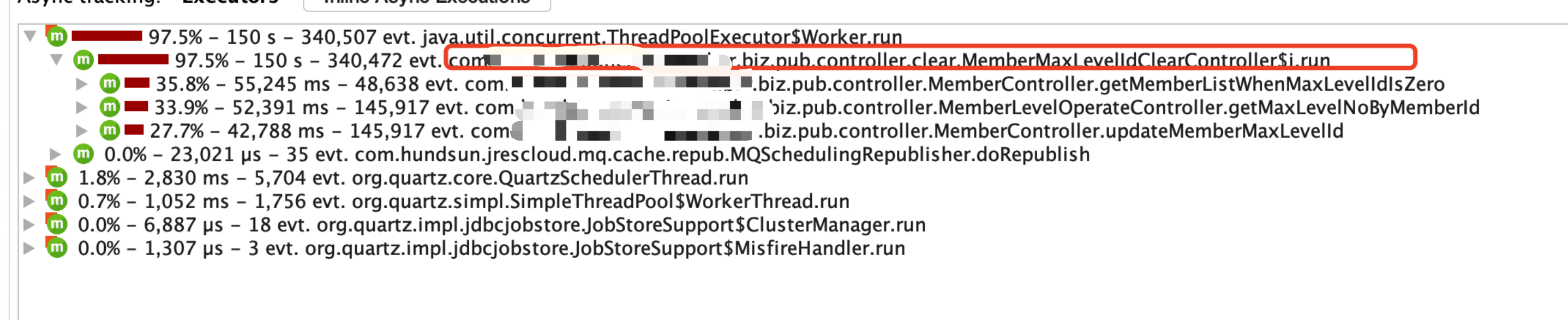
跟业务那边交流是,代码里面脏数据导致陷入了死循环可能是 。
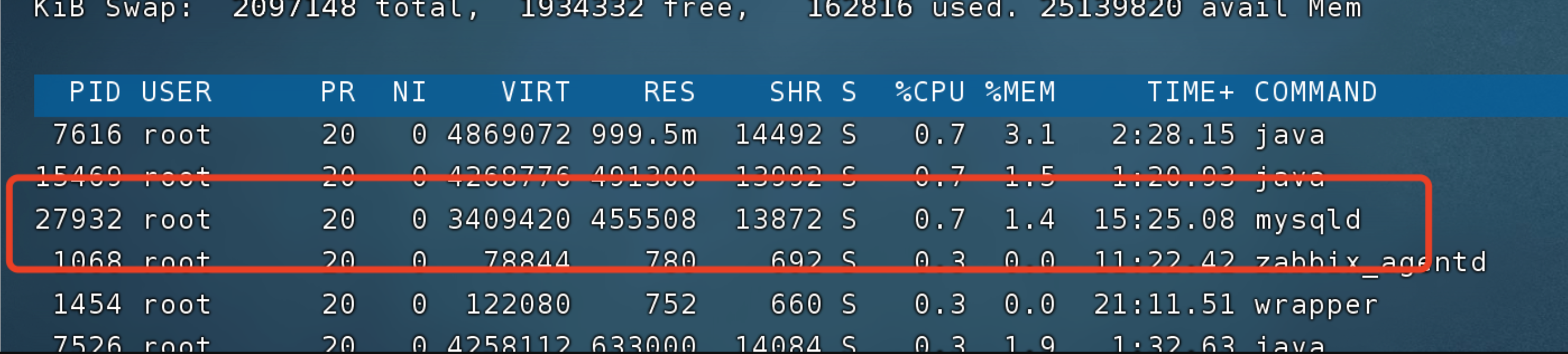
业务开发解决配合问题了之后,查看一切性能指标恢复正常。
最终,定时任务 每秒 update 几十条数据,mysql cpu负载恢复正常。

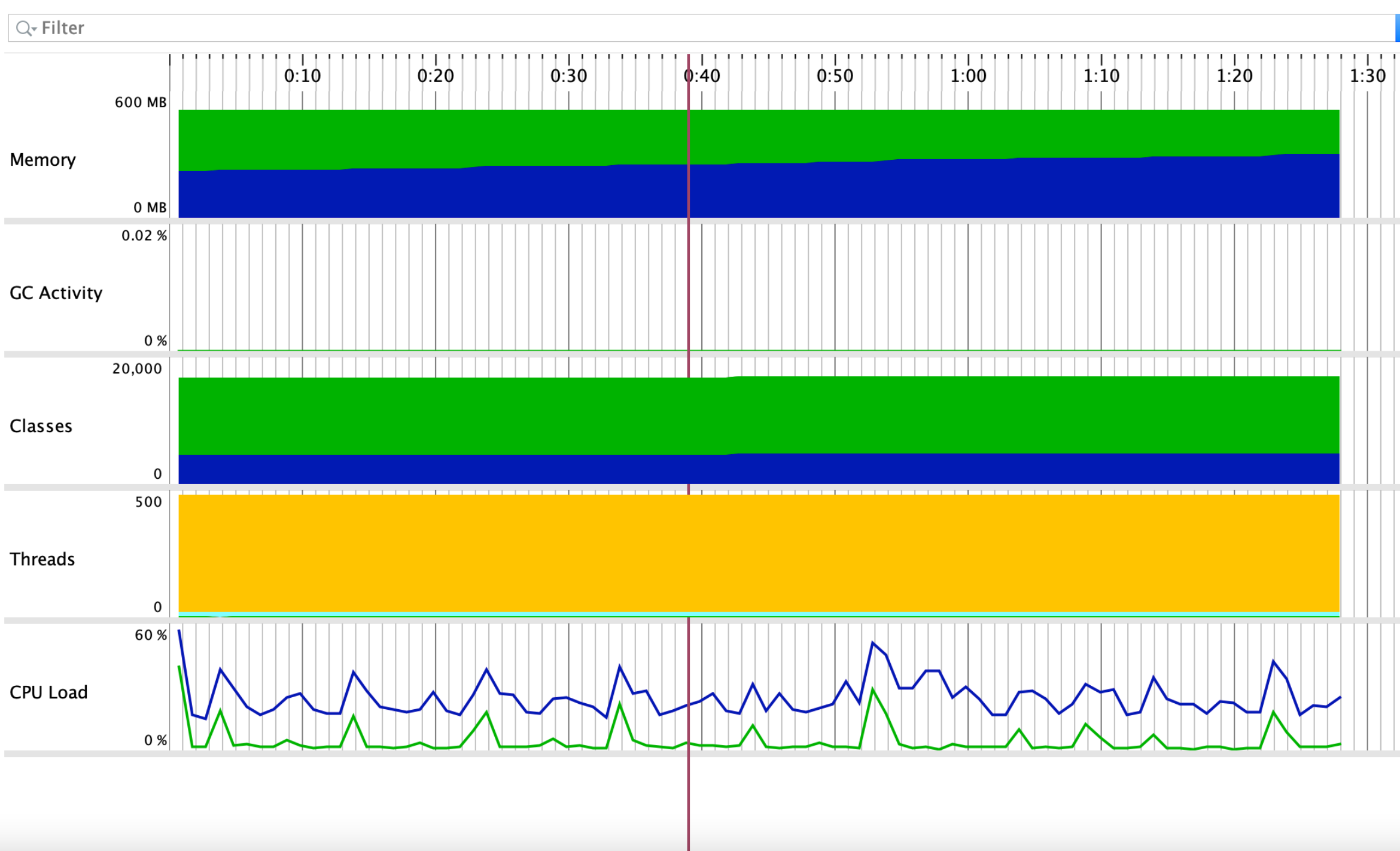
后面开发环境没出现过,CannotCreateTransactionException,这类问题。
说点个人心得
掌握各种工具,并知道工具的边界。
- arthas 是一个查看实时日志的工具集,也可以窥探内存属性,代码定位是强项,性能问题排查是它的短板。
- Jprofier是一个诊断器,可以可视化实时的展示项目所有指标,但是代码定位是它的短板,不够灵活。
- gceasy gc日志在线分析。
- Percona Toolkit,是一个mysql 分析的工具包,慢查询日志分析,以及mysql健康状态检测。
- redis AOF文件分析工具hiredis AOF分析
- 适当的代码阅读能力,比如有时候发现连接频繁关闭打开,这时候需要阅读源码了解框架的机制,判断是否是框架机制导致,而不是异常情况。(可以配合arthas命令,查看运行时属性值)
- 掌握普通查看命令行组合使用
比如,针对某个线程,代码的定位可以如下操作。
1.确定哪个进程PID的cpu异常高
top或htop,找到cpu异常高的进程PID
2、确定该进程下的哪个线程PID的cpu异常高
top -Hp 进程PID,找到cpu异常高的线程PID
3、打印该线程十六进制地址
printf "%x\n" 线程PID,获取到十六进制地址
4、确定是在执行程序的哪段代码
jstack 进程PID | grep -A30 十六进制地址
在掌握了这些工具后,在排查问题的时候,思路更广阔一些,不至于只会百度。找错就是一个大胆假设,小心求证的过程,你掌握的这些工具就作为你求证的工具。
易现问题
基本性能问题,比如慢查询,gc异常。基本使用arthas就能能解决。
这种问题一般,大概心理有数,哪个接口,哪段代码,基本的排除法就能够解决这种问题。使用arthas的trace,和 expian 基本可以大致定位问题。
这里我有几点心得,通常是异常频次比较高的几个类型
-
for循环里不要做io操作,包括本地io,远程io。有的同学喜欢在for循环里操作redis,或者本地磁盘,这种很容易引起性能问题。一个接口一次for循环,100次来说,每次远程io即便只花费2毫秒,这个for循环跑完,也至少200ms,还不算其他逻辑。
-
慢查询问题,通常是没有好好利用上索引导致,能使用联合索引的尽量使用联合索引,因为联合索引的唯一性是高于单个索引的。索引的效率通常是唯一性越高的索引查询效率越高。
-
大数据量查询问题,这点尤其在定时任务上明显,有的人,认为定时任务不需要考虑性能,在写sql脚本的时候马虎,比如不做分页,一次返回上万,几十万条数据,这样会导致俩个问题。1.mysql的负载受不了,会通过mysql级联影响到其他应用。2.java项目oom。
这些问题,通常使用arthas和pt-query-digest工具包,基本就可以一目了然,比较容易定位。
非易现问题
-
有的问题不是一下子能定位到的,这类问题通常,由一个核心问题,级联引发很多种不同的现状,不好定位排查,它可能由多方引起,这种情况就需要借助上面介绍的工具,慢慢试探,找蛛丝马迹,一点点抽丝剥茧,最终解决问题。
-
看日志,不要看一方的,要多方查看比对确保排查大方向是正确的,比如,redis连不上,到底是服务器网络的问题,还是redis自身的问题。
-
排查问题有节点思路,理清大概流程,把大流程分为多段,大概定位到问题具体在哪个段上发生,再重点关注该段上的动作。