介绍:Hystrix源自2011年Netflix的弹性工程项目,名字取自「豪猪」,寓意其会让系统拥有弹性、防御和容错的能力。经过了多年的发展,目前项目已进入停止更新的维护模式,官方给出的解释是他们的研究重点已从预先配置的方式转到实时自适应的方向,推荐新项目使用活跃的resilience4j,但Hystrix提出的概念和设计思想任然值得我们研究和借鉴。
本文从几个问题入手探讨一下Hystrix,看文之前可以带这这些问题略微思考一下。
- Hystrix中用了哪些设计模式?
- Hystrix中的断路器,各种隔离策略,监控是如何实现的?
- Hystrix有很多模块,这些复杂的模块如何结合起来的,如何做到开闭原则的,哪些部分可扩展?
- hytrix是基于rxjava的流控框架,为什么基于rxjava,或者基于rxjava可以让那些功能的实现变得方便?
Hystrix中有哪些设计模式
Hystrix中的观察者模式
Hystrix框架是基于rxjava框架开发的流控工具,rxjava是消息监听模式,所以首先Hystrix框架中第一种设计模式是基于rxjava的消息监听模式(也称作观察者模式)
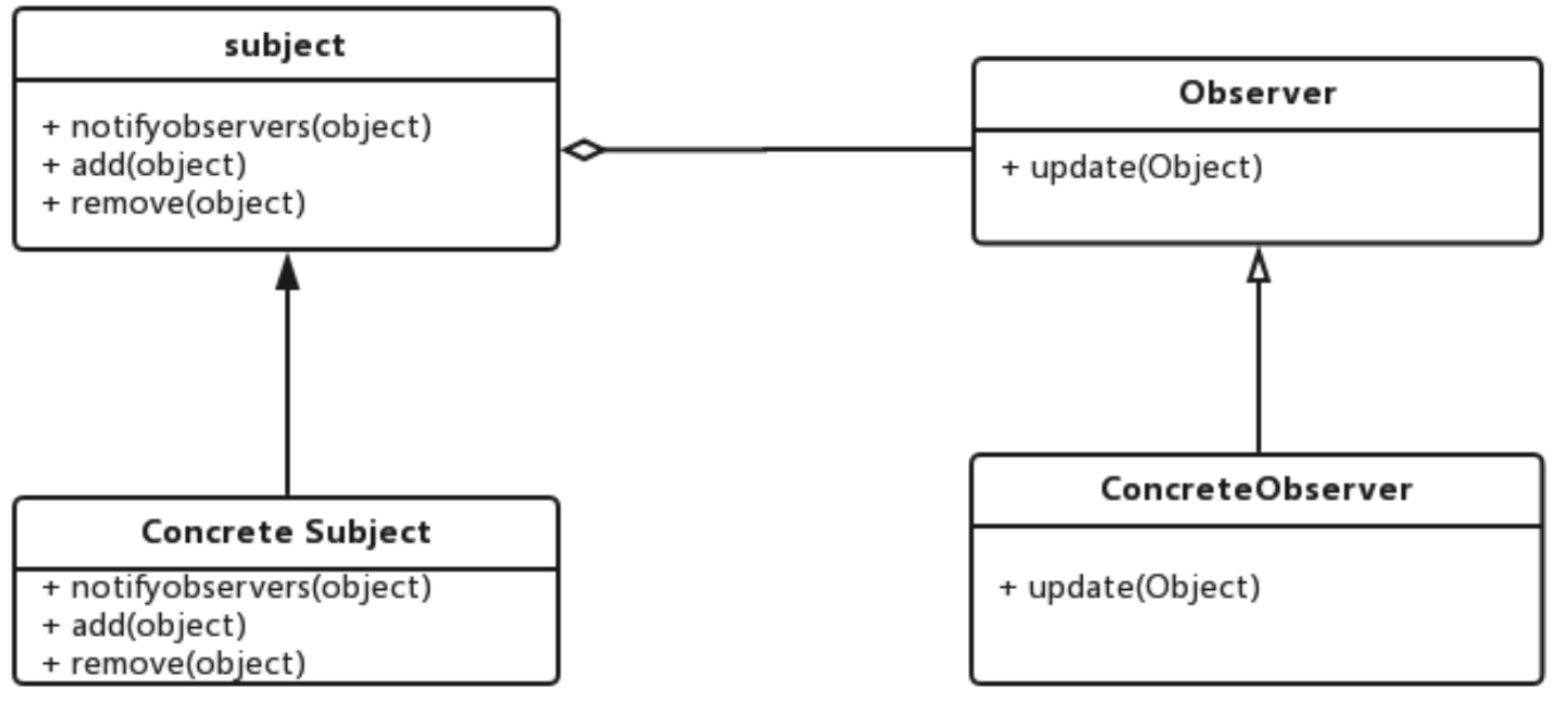
观察者模式也叫发布订阅模式。此模式的角色中有一个可观察的主题对象Subject,有多个观察者Observer去关注它。当Subject的状态发 生变化时,会自动通知这些Observer订阅者,令Observer
做出响应。在整个观察者模式中一共有4个角色:
(1) Subject (抽象主题) : Subject抽象主题的主 要职责之一为维护Observer观察者对象的集合,集合里的所有观察者都订阅过该主题。Subject抽象主题负责提供一些接口,可以增加、删除和更新观察者对象。
(2) ConcreteSubject (具 体主题) : ConcreteSubject用于 保持主题的状态,并且在主题的状态发生变化时给所有注册过的观察者发出通知。具体来说,ConcreteSubject需 要调用Subject (抽象主题)基类的通知方法给所有注册过的观察者发出通知。
(3) Observer (抽象观察者) :观察者的抽象类定义更新接口,使得被观察者可以在收到主题通知的时候更新自己的状态。
(4) ConcreteObserver (具 体观察者) :实现抽象观察者Observer所定义的更新接口,以便在收到主题的通知时完成自己状态的真正更新。
关系图如下:
而rxjava中的观察者模式略有区别,多了弹射器,和消息队列的概念。弹射器负责弹射消息。消息队列负责缓存消息。
主题会负责消息序列缓存,这一点像经典的生产者/消费者模式。在经典的生产者/消费者模式中,生产者生产数据后放入缓存队列,自己不进行处理,而消费者从缓存队列里拿到所要处理的数据,完成逻辑处理。从这点来说,RxJava借鉴了生产者消费者模式的思想。
这也是导致了hytrix使用RxJava的原因之一,在单线程中,可做到俩个逻辑之间的,隔离,削峰,背压功能。
Hystrix中的command设计模式是什么
Hystrix中为了有效的监控每个请求的生命周期和异常,将每个任务包裹成HystrixCommand。
这些异常计数,异常信息,是后面更新断路器状态的数据基础,是qps流控统计,失败率统计,等等统计的数据基础,command设计模式是Hystrix的内核思想,如果说用鸡和鸡蛋类比它和其他功能的话,它就是Hystrix中的鸡。
言归正传,我们来思考这俩个问题
command设计模式是什么?command设计模式在Hystrix中使用?
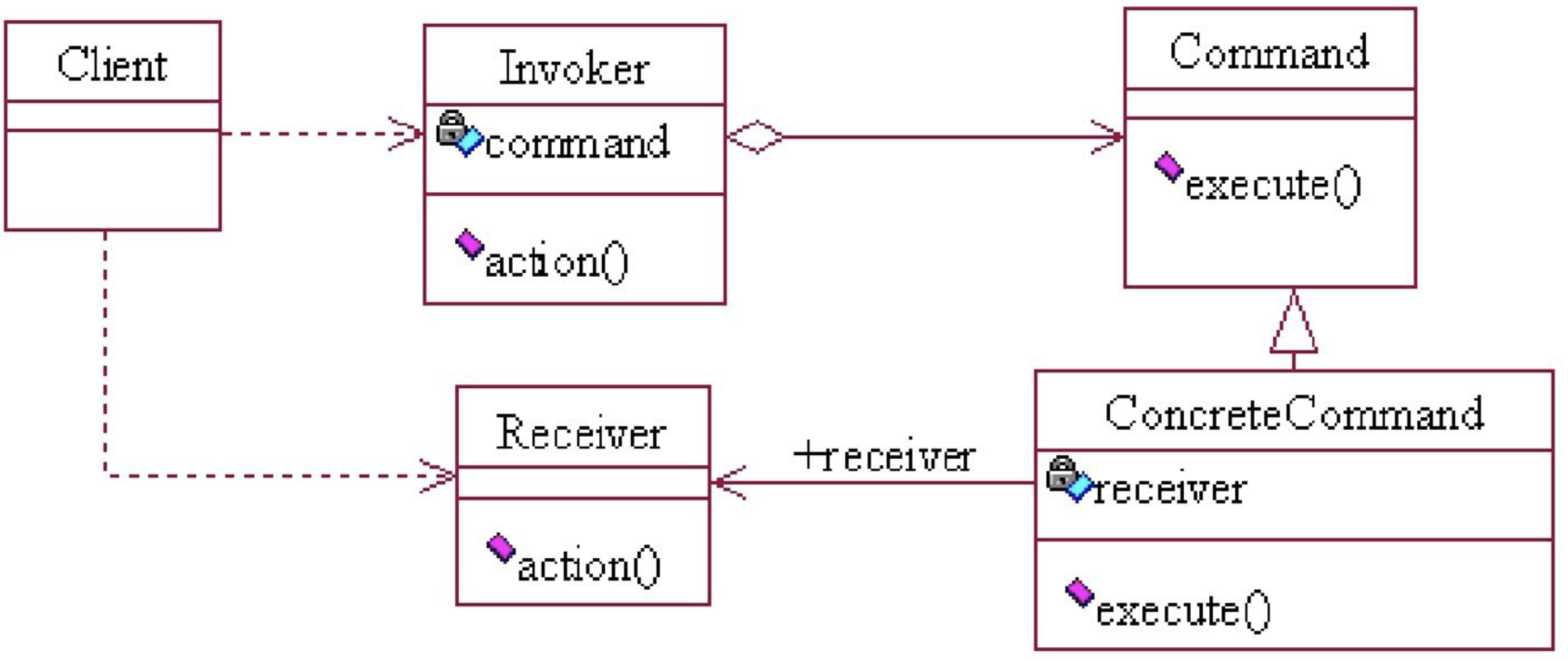
command设计模式是什么是行为设计模式的一种,又称为行为模式,或者交易模式,本质功能为了解耦代码,增加代码的扩展性。
命令模式中有如下4个角色。
- 命令(Command)角色:该角色声明一个给所有具体命令类的抽象接口,
定义需要执行的命令。 - 具体命令(Concrete Command)角色:该角色定义一个接收者和行为之
间的弱耦合,实现命令方法,并调用接收者的相应操作。 - 调用者(Invoker)角色:该角色负责调用命令对象执行请求。
- 接收者(Receiver) 角色:该角色负责具体实施和执行一个请求。
Hystrix 中的command设计模式改造了哪些?
1.把每个任务,分成,执行成功,执行失败,执行异常,三种事件,这三种事件,作为我们Hystrix的统计数据源,断路器依赖数据,用于后面的rxjava的事件源,
2.封装了命令运行逻辑(run)和服务调用失败时回退逻辑(getFallback)。
3.Hystrix 中的command 融合了隔离的概念,比如,如果设置线程池隔离,将会使用不同应用的线程池作为调用者。(不同的隔离机制后文会讲)
Hystrix中的隔离机制,限流策略,断路器都是如何实现的?
什么是舱壁功能,Hystrix中的隔离策略有哪些?
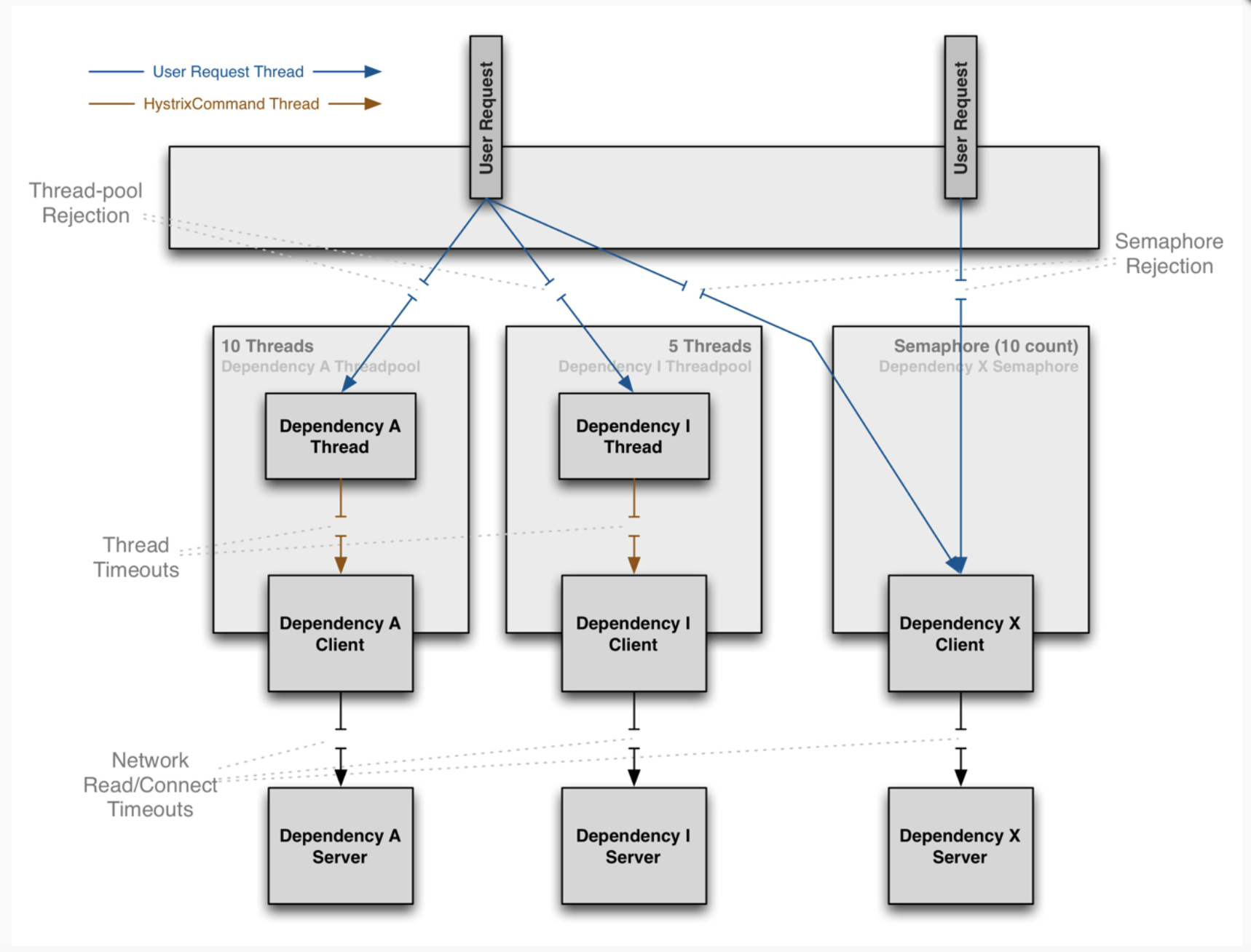
Hystrix使用了多种隔离技术(舱壁隔离、泳道和断路器模式)来限制任何一个依赖项的影响。所谓舱壁隔离源自造船技术,货船为了防止漏水和火灾的扩散会将货仓分隔为多个,当发生灾害时将所在货仓进行隔离就可以降低整艘船的风险。Hystrix对不同的依赖项利用不同的线程池进行隔离,相同依赖项的请求使用不同的线程进行隔离,分别对应舱壁隔离和泳道。每个CommandKey代表一个依赖抽象,相同的依赖要使用相同的CommandKey名称,依赖隔离的根本就是对相同CommandKey的依赖做隔离。默认情况下,HystrixCommand使用线程池隔离,可以通过设置线程池的大小来限制请求数量,也可以通过修改配置项调整请求队列的大小,HystrixObservableCommand使用信号量隔离。信号量不需要线程切换,开销小,但不支持异步和超时,只有在非网络请求或者大量访问线程开销很大的情况下才考虑使用信号量隔离,否则默认的线程隔离已满足大部分使用场景的需求。
线程池隔离:
Hystrix既可以为HystrixCommand命令默认创建一个线程池, 又可以关联上一个指定的线程池。每一个线程池都有一个Key,名为Thread Pool Key (线程池名)。如果没有为HystrixCommand指定线程池,Hystrix就 会为HystrixCommand创建一个与Group Key ( 命令组Key)同名的线程池,当然,如果与Group Key同名的线程池已经存在,就直接进行关联。也就是说,默认情况下,HystrixCommand命 令的Thread Pool Key与Group Key是相同的。总体来说,线程池是Hystrix中RPC调用隔离的关键,所有的监控、调用、缓存等都围绕线程池展开。
信号量隔离:
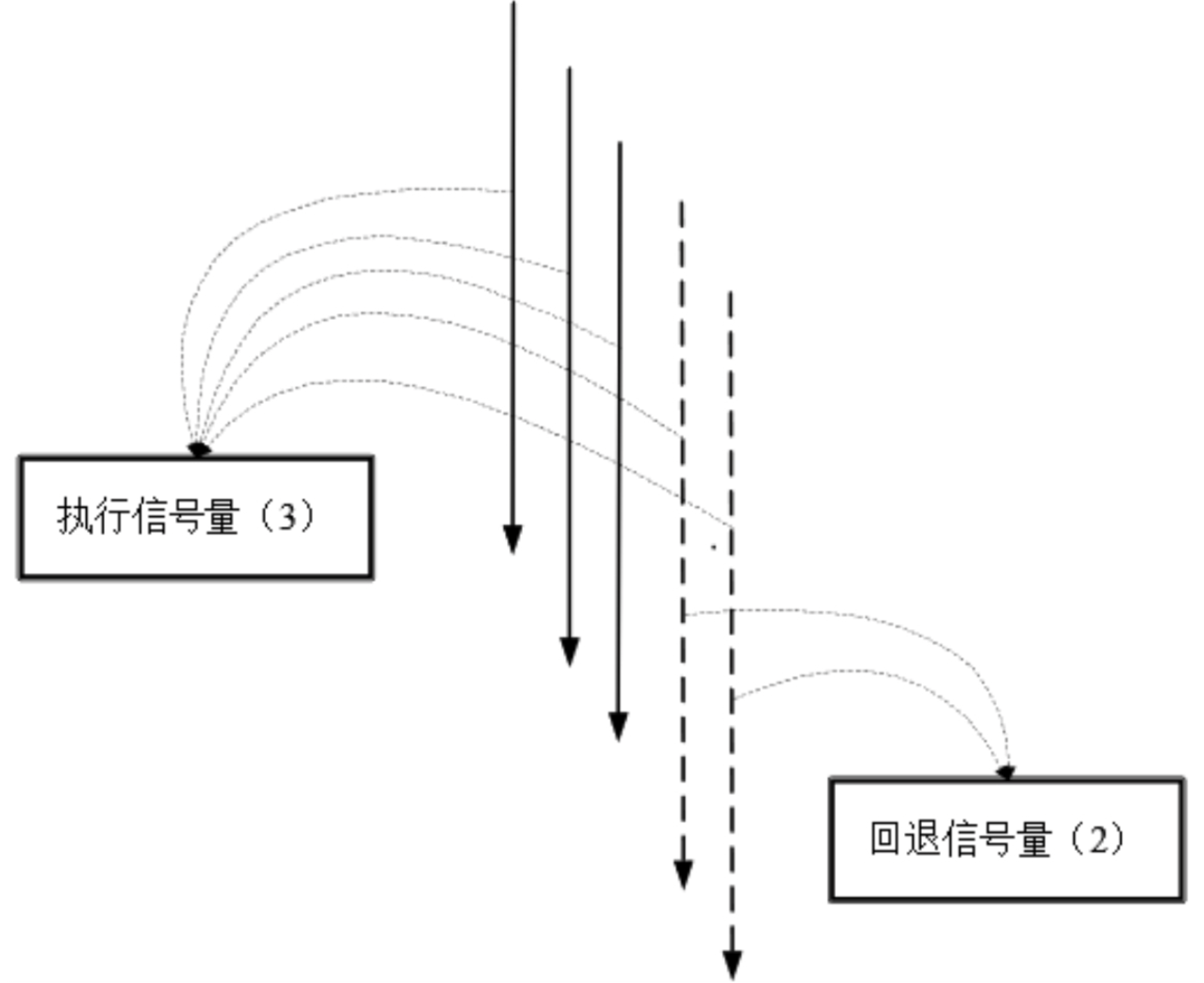
除了使用线程池进行资源隔离之外,Hystrix还可以使用信号量机制完成资源隔离。信号量所起到的作用就像一个开关,而信号量的值就是每个命令的并发执行数量,当并发数高于信号量的值时就不再执行命令。比如,如果Provider A的RPC信号量大小为10,那么它同时只允许有10个RPC线程来访问服务Provider A,其他的请求都会被拒绝,从而达到资源隔离和限流保护的作用。Hystrix信号量机制不提供专用的线程池,也不提供额外的线程,在获取到信号量之后,执行HystrixCommand命 令逻辑的线程还是之前Web容器的IO线程。信号量可以细分为run执行信号量和fallback回退信号量。
I0线程在执行HystrixCommand命令之前需要抢到run执行信号量,成功之后才允许执行HystrixCommand.run()方法。如果争抢失败,就准备回退,但是在执行HystrixCommand.getFallback()回退方法之前,还需要争抢fallback回退信号量,成功之后才允许执行HystrixCommand.getFallback()回退方法。如果都获取失败,操作就会直接终止。假设有5个Web容器的IO线程并发进行RPC远程调用,但是执行信号量的大小为3,也就是只有3个IO线程能够真正地抢到run执行信号量,这些线程才能发起RPC调用。剩下的两个IO线程准备回退,去抢fallback回退信号量,争抢成功后执行HystrixCommand.getFallback()回退方法。
逻辑隔离:
基于rxjava的消费者设计模式,可以把一个逻辑拆分为上游和下游,利用rxjava的消息队列机制,背压机制,来实现俩个逻辑的隔离,俩个逻辑的执行速度,执行成功率,即不会形成强依赖,但也可以互相控制对方。
背压: 当上下游的流操作处于不同的线程时,如果上游弹射数据的速度快于下游接收处理数据的速度,对于那些没来得及处理的数据就会造成积压,这些数据既不会丢失,又不会被垃圾回收机制回收,而是存放在一个异步缓存池中,如果缓存池中的数据一直得不到处理,越积越多,最后就会造成内存溢出,这便是响应式编程中的背压问题。
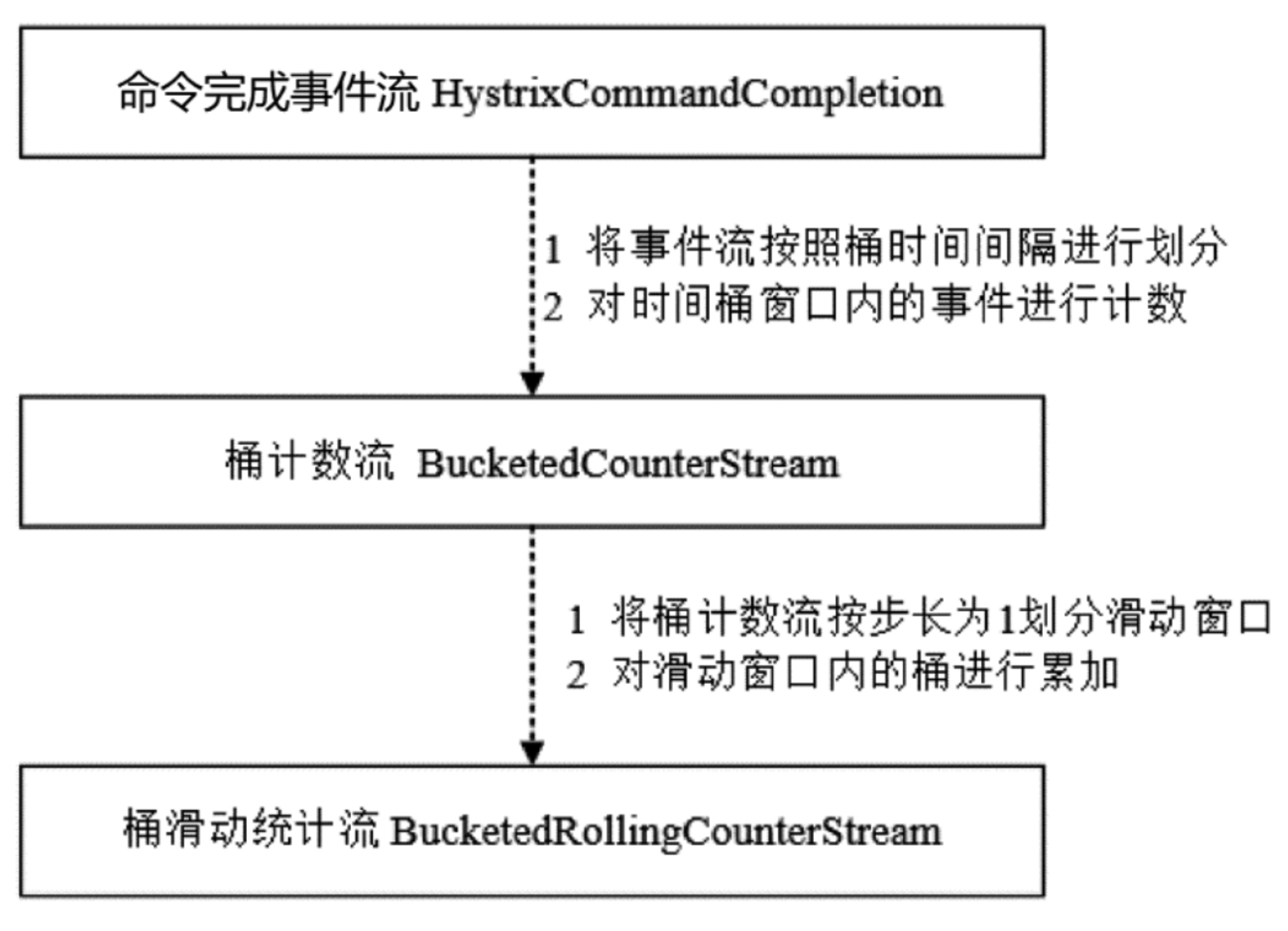
滑动窗口在Hystrix中是如何实现的?
滑动窗口在Hystrix中是基于rxjava实现的,很多人有疑问,滑动窗口难度并不复杂,为什么要多此一举用rxjava来实现,其实严格说,它并不仅仅实现限流功能,它是实现数据统计功能顺带手把限流功能实现了。
Hystrix滑动窗口的核心实现是使用RxJava的window操作符(算子)来完成的。使用RxJava实现滑动窗口还有一大好处就是可以依赖RxJava的线程模型来保证数据写入和聚合的线程安全。
在Hystrix中,业务逻辑以命令模式封装成了一个个命令(HystrixCommand) ,每个命令执行完成后都会发送命令完成事件( HystrixCommandCompletion)到HystrixCommandCompletion Stream命令完成事件流。HystrixCommandCompletion是 Hystrix中核心的事件,它可以代表某个命令执行成功、超时、异常等各种状态,与Hystrix熔断器的状态转换息息相关。桶计数流BucketedCounterStream是一个抽象类,提供了基本的桶计数器实现。用户在使用Hystrix的时候一般 都要配置两个值: timelnMilliseconds (滑动窗口的长度,时间间隔)和numBuckets (滑动窗口中的桶数),每个桶对应的时间长度就是bucketSizelnMs=timelnMilliseconds/numBuckets,该时间长度可以记为一个时间桶窗口BucketedCounterStream每隔一个时间桶窗口就把这段时间内的所有调用事件聚合到一个累积桶内。
下面是一段BucketedCounterStream初始化的代码:
protected BucketedCounterStream(final HystrixEventStream<Event> inputEventStream, final int numBuckets, final int bucketSizeInMs,
final Func2<Bucket, Event, Bucket> appendRawEventToBucket) {
this.numBuckets = numBuckets;
this.reduceBucketToSummary = new Func1<Observable<Event>, Observable<Bucket>>() {
@Override
public Observable<Bucket> call(Observable<Event> eventBucket) {
return eventBucket.reduce(getEmptyBucketSummary(), appendRawEventToBucket);
}
};
final List<Bucket> emptyEventCountsToStart = new ArrayList<Bucket>();
for (int i = 0; i < numBuckets; i++) {
emptyEventCountsToStart.add(getEmptyBucketSummary());
}
this.bucketedStream = Observable.defer(new Func0<Observable<Bucket>>() {
@Override
public Observable<Bucket> call() {
return inputEventStream
.observe()
.window(bucketSizeInMs, TimeUnit.MILLISECONDS) //bucket it by the counter window so we can emit to the next operator in time chunks, not on every OnNext
.flatMap(reduceBucketToSummary) //for a given bucket, turn it into a long array containing counts of event types
.startWith(emptyEventCountsToStart); //start it with empty arrays to make consumer logic as generic as possible (windows are always full)
}
});
}
BucketedCounterStream的构造函数里接收4个参数:
第一个参数inputEventStream是一个HystrixCommandCompletionStream命令完成事件流,每个HystrixCommand命 令执行完成后,将发送的命令完成事件最终都通过inputEventStream弹射来;
第二个参数numBuckets为设置的滑动窗口中的桶数量;
第三个参数bucketSizelnMs为每个桶对应的时间长度;
第四个参数为将原始事件统计到累积桶(Bucket) 的回调函数。
BucketedCounterStream的核心是window操作符,它可以将原始的完成事件流按照时间桶的长度bucketSizelnMs进行拆分,并将这个时间段内的事件聚集起来,输出一个Observable,然后通过flapMap操作将每一个Observable进行 扁平化。具体的flapMap扁平化操作是通过调用reduceBucketToSummary方法完成的,该方法通过RxJava的reduce操作符进行“聚合”操作,将Observable中的一串事件归纳成一个累积桶。
流控桶数据结构图如下:

*流扭转图如下:
断路器执行流程
断路器模式在Hystrix的架构中也起到了至关重要的作用,其设计了「滚桶」的数据结构,滑动窗口被分成N个桶,桶中保存成功、失败、拒绝、超时和百分位信息,而且总是从最新的N个桶中读取Metrics信息。Hystrix早期是利用HystrixRollingNumber和HystrixRollingPercentile来存放聚合数据,1.5.x版本以后变为利用响应式编程的一种实现RxJava和Stream来存放和处理聚合数据了。当统计数据达到错误率阈值时,「断路器」将短路某个依赖服务的后续请求,直到恢复期结束,若恢复期结束根据统计数据「断路器」判定「电路」仍然未恢复健康,「断路器」会再次关闭「电路」。
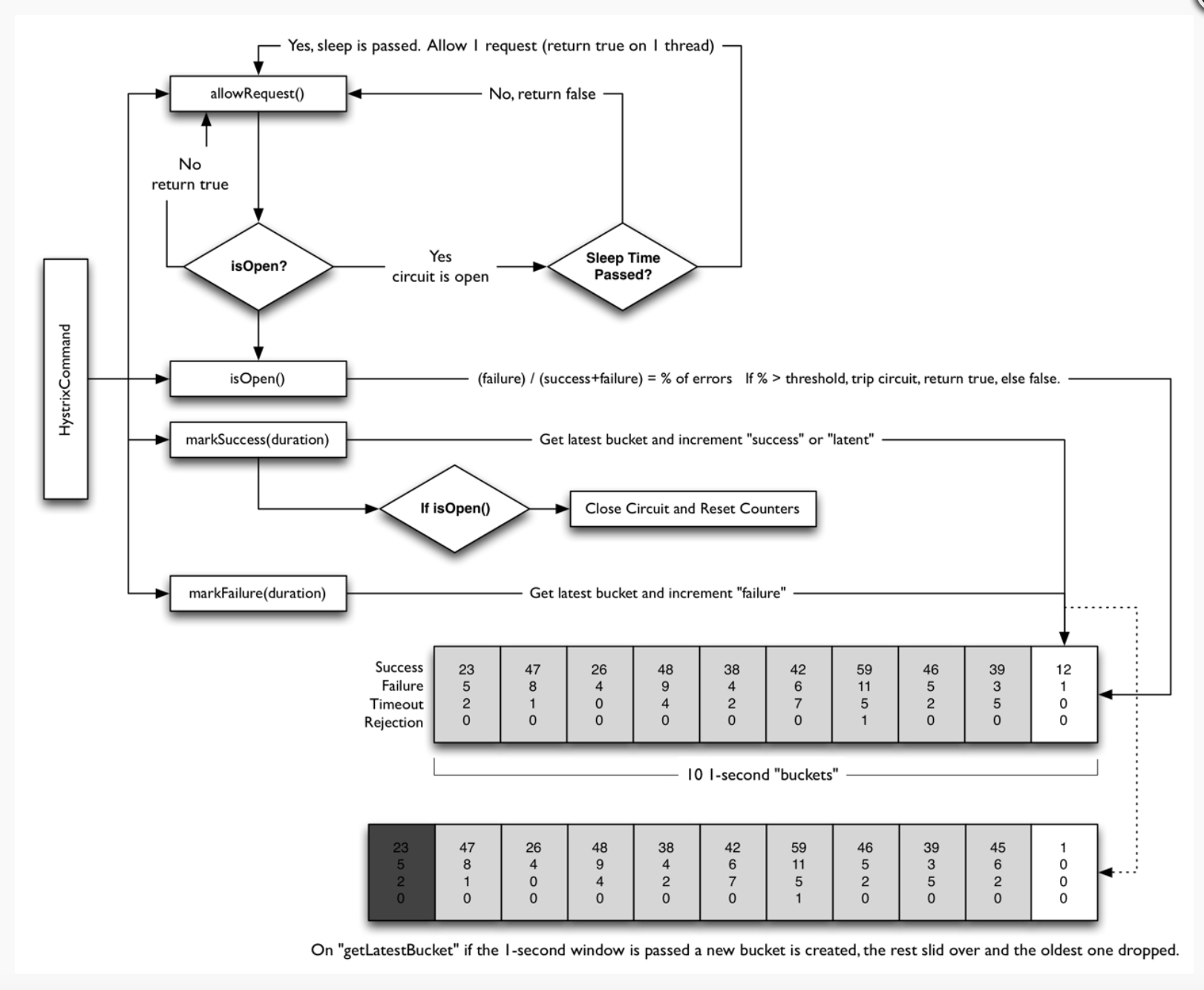
流程如下:
构造Hystrix命令对象,并调用run方法
Hystrix将检查断路器开关是否打开,如果打开,则调用回退方法
如果断路器开关关闭,Hystrix将检查当前服务的线程池,看是否可以接受新请求。如果线程池已满,则调用回退方法
如果线程池可以接受新请求,那么Hystrix可以调用run方法来执行run逻辑
如果run执行失败,则调用回退方法并将健康状态返回到Hystrix指标
如果run执行超时,则调用回退方法并将健康状况返回到Hystrix指标
如果run成功执行,则返回正常结果
如果回退方法成功执行,它将返回回退执行结果
如果回退方法执行失败,则抛出异常
这些复杂的功能如何结合起来,如何做到开闭原则的,哪些部分可扩展?
Hystrix中的类可分为这几类
- 一个主类用于控制生命周期 (com.netflix.Hystrix.Hystrix)。
- 上游事件类,作为所有事件触发入口 (HystrixCommandCompletionStream)。
- 下游事件类,作为所有应用统计的支流,订阅自己需要的事件,生成自定义报表这各模块可以接入普罗米修斯,可自定义模块。(BucketedCumulativeCounterStream)
- 工具类,用于封装上游或者下游事件类等等的调用接口。可自定义模块。(HystrixMetrics)
- 各种abastract对象,用于复用各种模板方法,比如AbstractCommand,HystrixMetrics,可自定义模块。(AbstractCommand)
流程梳理
- 主类先执行,将所有的事件类初始化,以约定的key保存到容器中,部分类为懒加载形式。
- 初始化一个HystrixCommand对象,先初始化AbstractCommand,AbstractCommand类中的各个统计类,线程池属性,从上面的容器中获取值,初始化。
- 执行HystrixCommand对象,类似于dubbo设计层面的aop方式,在方法调用前后,做限流,熔断,监控逻辑。
- 通过在父类中定义空函数策略,将包括流控,统计,等等功能所有流程的代码架子搭好,具体函数,可以通过继承实现去实现一些定制化,配置化的功能。
代码解析
主类,控制整个框架的生命周期。
com.netflix.Hystrix.Hystrix#_reset
private static void _reset() {
// clear metrics
HystrixCommandMetrics.reset();
HystrixThreadPoolMetrics.reset();
HystrixCollapserMetrics.reset();
// clear collapsers
HystrixCollapser.reset();
// clear circuit breakers
HystrixCircuitBreaker.Factory.reset();
HystrixPlugins.reset();
HystrixPropertiesFactory.reset();
currentCommand.set(new ConcurrentStack<HystrixCommandKey>());
}
上游事件类
一个上游事件,n个下游事件,一次触发n次异步执行。 (Hystrix中第一种解耦方式)
com.netflix.Hystrix.metric.HystrixCommandCompletionStream#getInstance
public static HystrixCommandCompletionStream getInstance(HystrixCommandKey commandKey) {
HystrixCommandCompletionStream initialStream = streams.get(commandKey.name());
if (initialStream != null) {
return initialStream;
} else {
synchronized (HystrixCommandCompletionStream.class) {
HystrixCommandCompletionStream existingStream = streams.get(commandKey.name());
if (existingStream == null) {
HystrixCommandCompletionStream newStream = new HystrixCommandCompletionStream(commandKey);
streams.putIfAbsent(commandKey.name(), newStream);
return newStream;
} else {
return existingStream;
}
}
}
}
下游事件类
下游中使用案例
com.netflix.Hystrix.metric.consumer.BucketedCumulativeCounterStream#BucketedCumulativeCounterStream
protected BucketedCumulativeCounterStream(HystrixEventStream<Event> stream, int numBuckets, int bucketSizeInMs,
Func2<Bucket, Event, Bucket> reduceCommandCompletion,
Func2<Output, Bucket, Output> reduceBucket) {
super(stream, numBuckets, bucketSizeInMs, reduceCommandCompletion);
this.sourceStream = bucketedStream
.scan(getEmptyOutputValue(), reduceBucket)
.skip(numBuckets)
.doOnSubscribe(new Action0() {
@Override
public void call() {
isSourceCurrentlySubscribed.set(true);
}
})
.doOnUnsubscribe(new Action0() {
@Override
public void call() {
isSourceCurrentlySubscribed.set(false);
}
})
.share() //multiple subscribers should get same data
.onBackpressureDrop(); //if there are slow consumers, data should not buffer
}
下游用上游stream生成新stream。
在com.netflix.Hystrix.AbstractCommand#executeCommandWithSpecifiedIsolation 中的
private Observable<R> executeCommandWithSpecifiedIsolation(final AbstractCommand<R> _cmd) {
if (properties.executionIsolationStrategy().get() == ExecutionIsolationStrategy.THREAD) {
// mark that we are executing in a thread (even if we end up being rejected we still were a THREAD execution and not SEMAPHORE)
return Observable.defer(new Func0<Observable<R>>() {
@Override
public Observable<R> call() {
executionResult = executionResult.setExecutionOccurred();
if (!commandState.compareAndSet(CommandState.OBSERVABLE_CHAIN_CREATED, CommandState.USER_CODE_EXECUTED)) {
return Observable.error(new IllegalStateException("execution attempted while in state : " + commandState.get().name()));
}
//这里发出事件
metrics.markCommandStart(commandKey, threadPoolKey, ExecutionIsolationStrategy.THREAD);
if (isCommandTimedOut.get() == TimedOutStatus.TIMED_OUT) {
// the command timed out in the wrapping thread so we will return immediately
// and not increment any of the counters below or other such logic
return Observable.error(new RuntimeException("timed out before executing run()"));
}
........
}
}
在AbstractCommand,命令执行过程中,调用metrics.markCommandStart触发事件,事件从上到下传递,依次执行各种维度统计逻辑。
abastract类实现模板方法
abastract类实现模板方法,通过继承来复用公共功能比如,AbstractCommand和HystrixCommand的关系 (Hystrix的第二种解耦方式)
public abstract class HystrixCommand<R> extends AbstractCommand<R> implements HystrixExecutable<R>, HystrixInvokableInfo<R>, HystrixObservable<R> {
/**
* Construct a {@link HystrixCommand} with defined {@link HystrixCommandGroupKey}.
* <p>
* The {@link HystrixCommandKey} will be derived from the implementing class name.
*
* @param group
* {@link HystrixCommandGroupKey} used to group together multiple {@link HystrixCommand} objects.
* <p>
* The {@link HystrixCommandGroupKey} is used to represent a common relationship between commands. For example, a library or team name, the system all related commands interact with,
* common business purpose etc.
*/
protected HystrixCommand(HystrixCommandGroupKey group) {
super(group, null, null, null, null, null, null, null, null, null, null, null);
}
...
}}
核心对象如何存储
公共对象的存储,基本依赖concurentHashMap,ThreadLocal数据结构,比如stream对象的存储
com.netflix.Hystrix.metric.HystrixCommandCompletionStream
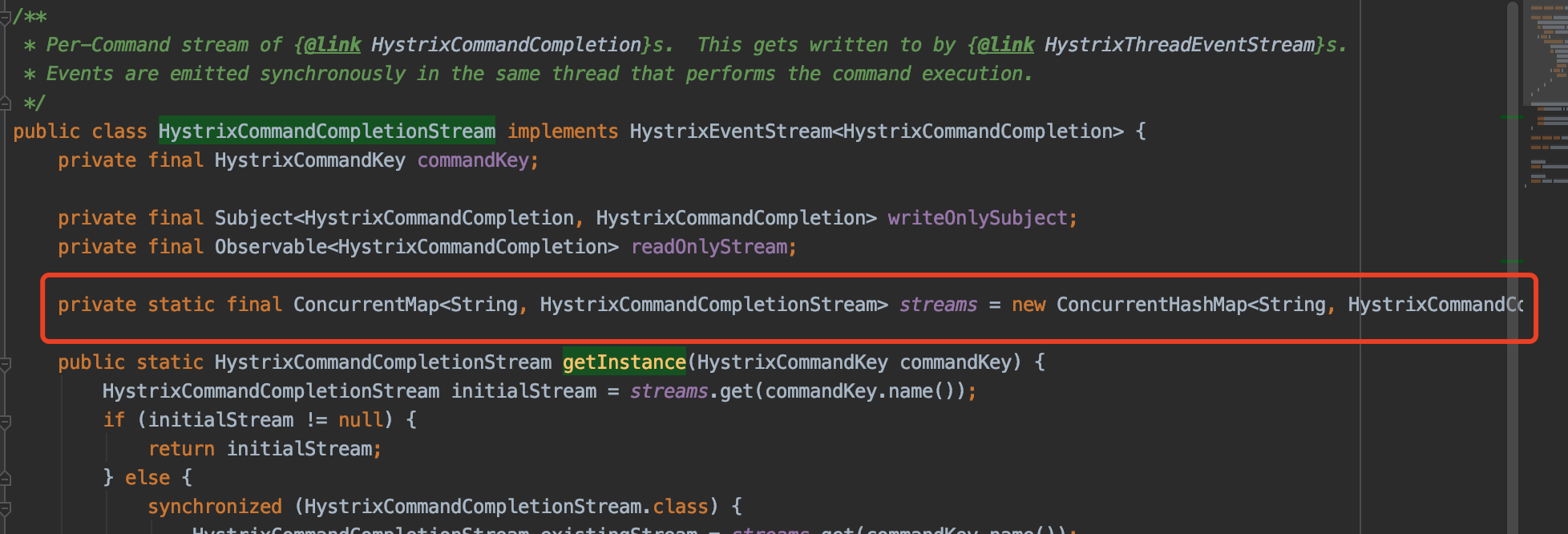
再比如隔离的线程池对象存储

为什么Hystrix中使用抽象类而不是接口?
Hystrix在设计中使用继承抽象基类而不是接口,官方给出的原因主要是为了方便维护类库,如果使用接口每新增一个功能就需要新加一个接口,而使用继承抽象基类,用户可以重写方法但不破坏默认实现,这样就可以在不破坏已有实现的情况下添加新功能。然而我们知道面向对象设计有一条原则「基于接口而不是继承」,Hystrix的选择究竟是否正确,或者说是否是因为公共类库的设计和普通业务系统的设计的区别导致了不同的选择,这值得我们思考,当然Java8后的default方法给了我们另一个选择。
源代码参考:https://github.com/Netflix/Hystrix
书籍参考:《rxjava反应式编程》,《高并发核心编程系列》