ZooKeeper提供分布式协调服务,应用非常广泛,虽然出现了其他服务发现组件,比如etcd、consul,但是仍然可以看到ZooKeeper在Kafka、Solr、Hbase、Stom等方面的应用。分布式锁是其中一个使用特性,分布式锁包含排他锁和共享锁两类锁。
1. 排他锁
1.1 简介
又称为写锁或者独占锁,是一种基本的锁类型。若事务T1对数据对象O1加上了排他锁,在加锁期间,仅允许事务T1对O1进行读取和更新操作,直到T1释放了锁,其他事务才能对这个数据对象进行任何类型的操作。
1.2 如何使用排他锁
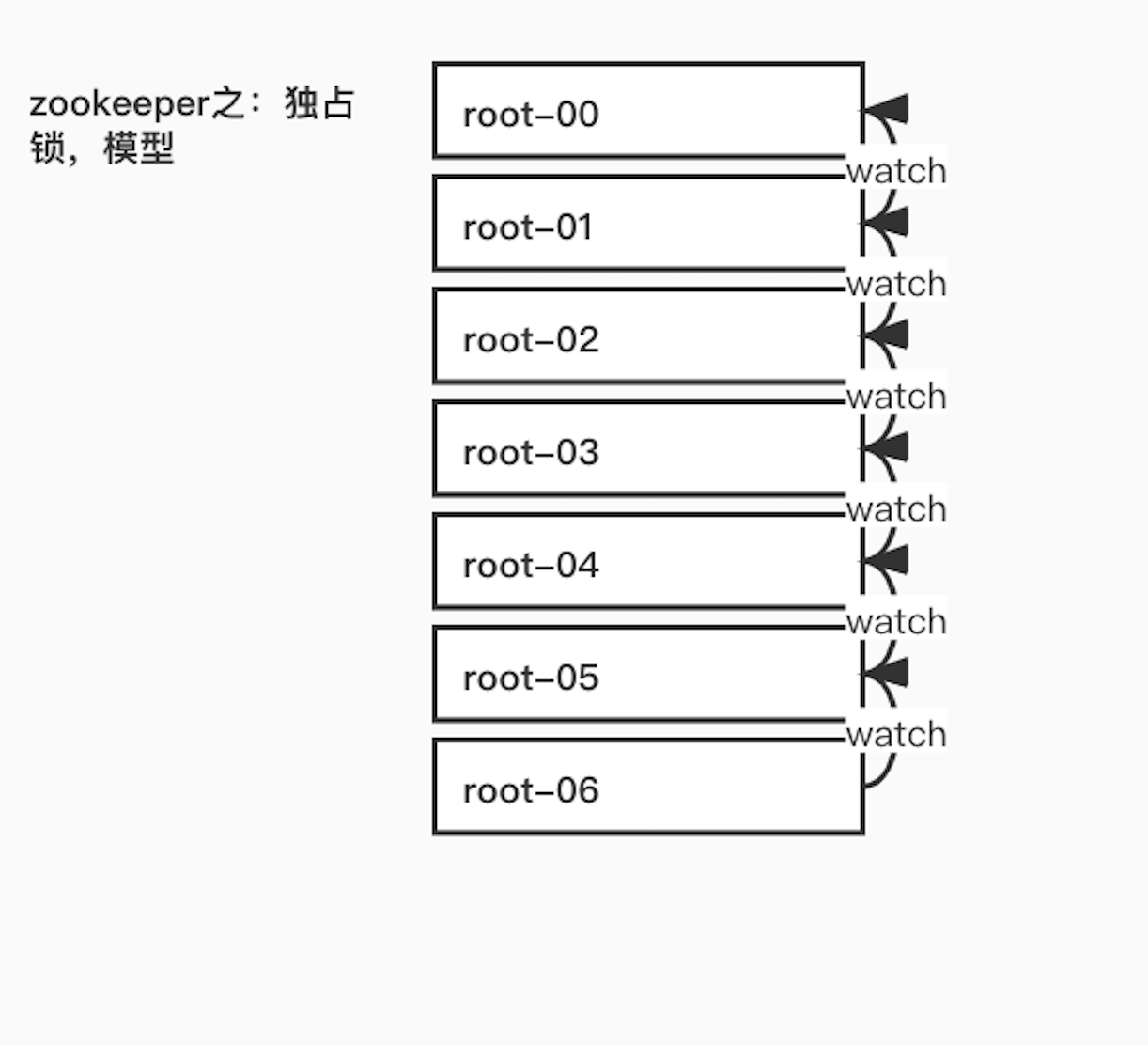
1)在Java开发中,有两种常见的方式来定义锁,分别是synchronized和ReentrantLock。ZooKeeper通过其上的一个数据节点表示一个锁,例如创建的临时节点/exclusive/lock就可以表示一个锁。
2)在获取排他锁时,所有客户端节点都会调用create()接口,在/exclusive下创建节点/exclusive/lock。ZK保证在所有客户端中,只有一个客户端能够创建成功,就可以认为该客户端获取到锁。同时,所有没有获取到锁的客户端需要在/exclusive/lock节点注册一个Watcher监听,以便实时监听lock节点的变更情况。
3)在下面的两种情况下,可能会释放锁。
(1)当前获取锁的客户端机器发生宕机,ZK上的临时节点会被移除。
(2)正常执行完业务逻辑后,客户端会主动删除创建的临时节点。
无论在哪种情况下移除了lock节点,ZK都会通知所有注册了Watcher监听的客户端。这些客户端在接收到通知后,重新发起分布式锁获取,即重复“获取锁”过程。
1.3 排他锁优化
问题:
对于上述的场景,当大量客户端去竞争锁的时候,会发生“惊群”效应。这里惊群效应指的是在分布式锁竞争的过程中,大量的"Watcher通知"和“创建/exclusive/lock”两个操作重复运行,并且绝大多数运行结果都创建节点失败,从而继续等待下一次通知。若在集群规模较大的情况下,会对ZooKeeper服务器以及客户端服务器造成巨大的性能影响和网络冲击。
改进:
1)客户端调用create()方法创建名为“/exclusive/lock-”节点,这里节点类型创建类型设置为EPHEMERAL_SEQUENTIAL;
2)客户端调用getChildren(“/exclusive”)方法来获取所有已经创建的子节点,若发现自身的节点序号是/exclusive目录下最小的点,则获得锁;否则,监视比自己创建的节点的序列号小的最大节点,进入等待。
3)这样,避免了"惊群效应",多个客户端共同等待锁,锁释放时只有一个客户端会被唤醒。
2. 共享锁
2.1 简介
又称为读锁,若事务T1对数据对象O1加上了共享锁,当前事务只能对O1进行读取操作,其他事务只能对这个数据对象加共享锁---直到该数据对象上的所有共享锁都被释放。
共享锁与排他锁的根本区别在于:加上排他锁之后,数据对象只对一个事务可见,而加上共享锁后,数据对所有事务都可见。
2.2 如何使用共享锁
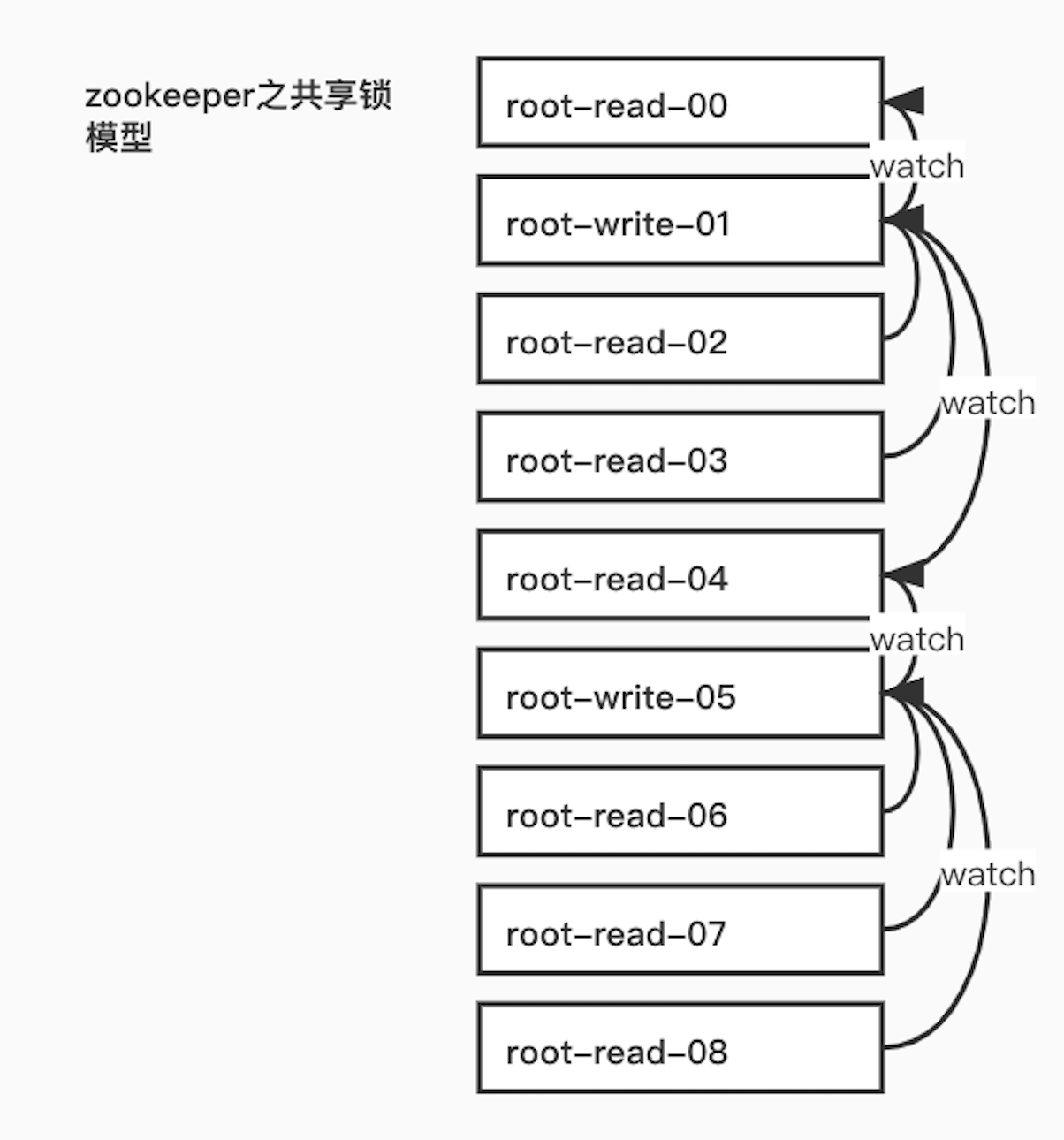
1)同样使用ZK上的数据节点表示一个锁,是一个类似于“/shared_lock/[Hostname]-请求类型-序号”的临时顺序节点,例如/shared_lock/192.168.0.1-R-0000000001就代表了共享锁。
2)在获取共享锁时,所有客户端都会到/shared_lock节点下创建一个临时顺序节点,若是读请求,则创建/shared_lock/192.168.0.1-R-0000000001;若是写请求,则创建/shared_lock/192.168.0.1-W-0000000001。
3)根据共享锁的定义,不同的事务都可以同时对同一个数据对象进行读取操作,而更新操作必须在当前没有任何事务进行读写操作的情况下进行。基于这个原则,我们来看看如何通过ZK的节点来确定分布式读写顺序,大致可以分为4个步骤:
(1) 创建完节点后,获取/shared_lock节点下的所有子节点,并对该节点注册子节点变更的Watcher监听。
(2) 确定自己的节点序号在所有子节点中的顺序。
(3) 对于读请求:若没有比自己序号小的子节点,或是所有比自己序号小的请求都是读请求,那么表明自己已经成功获取到了共享锁,同时开始执行读取逻辑;若比自己序号小的子节点中有写请求,那么需要进入等待。
对于写请求:若自己是序号最小的子节点,则执行读取逻辑;否则进入等待。
(4) 接收到Watcher通知后,重复步骤(1)。
2.3 共享锁优化
问题:
对于上述的场景,当大量客户端去竞争锁的时候,会发生“惊群”效应。这里惊群效应指的是在分布式锁竞争的过程中,大量的"Watcher通知"和“子节点列表获取”两个操作重复运行,并且绝大多数运行结果都判断自己并非是序号最小的节点,从而继续等待下一次通知。若在集群规模较大的情况下,会对ZooKeeper服务器以及客户端服务器造成巨大的性能影响和网络冲击。
改进:
上面提到的共享锁实现,从整体思路上来说完全正确。这里的主要改动在于:每个锁竞争者只需要关注shared_lock节点下序号比自己小的那个节点是否存在即可,具体改进如下所示:
1)客户端调用create()方法创建一个类似于“shared_lock/[Hostname]-请求类型-序号”的临时顺序节点。
2)客户端调用getChildren()接口来获取所有已经创建的子节点列表,注意,这里不注册任何Watcher。
3)若无法获取共享锁,调用exist()对比自己小的节点注册Watcher。
读请求:向比自己序号小的最后一个写请求节点注册Watcher监听。
写请求:向比自己序号小的最后一个节点注册Watcher监听。
4)等待Watcher通知,继续进入步骤2。
3. 注意事项
创建的节点应该是临时节点还是顺序节点?这两种选择各有利弊。
1)使用EPHEMERAL会引出一个风险:在非正常情况下,网络延迟比较大出现session timeout,ZooKeeper就会认为该client已关闭,从而销毁其id标识,竞争资源的下一个id就可以获取锁。这时可能两个process同时拿到锁在跑任务,设置好sessionTimeout很重要,不要跨机房访问。
2)同样使用PERSISTENT同样会存在一个死锁的风险,进程异常退出后,对应的竞争资源id一直没有删除,下一个id一直无法获取锁对象。
3)至于是否使用优化后的分布式锁,开发人员可以灵活掌握。在集群规模不大、网络资源丰富的情况下,之前的实现方案比较简单实用;若集群规模达到一定程度,希望可以精细化地控制分布式锁机制,可以尝试改进后的分布式锁实现。