为什么要构造DSL
DSL(Domain Specific Language)全称是领域特定语言,是一种针对特定应用领域的计算机语言。相对的是GPL(General Public Language)例如Java,C++,JavaScript 均属于这一类。到这里就好理解了,DSL,就是在业务域使用场景确定的情况下,更具具体的场景创造的一种编程语言。到这里大家肯定会有疑问?Java能做的事情为什么需要特定的语言来做呢?经历过编程革命的人一定了解语言发展趋势,汇编->C->Java->Go,就拿最新的java->go来说吧,既然Java什么都能做,为什么Go会出现?
不卖关子了揭开谜底:核心是效率的提升,50行汇编代码和50行java代码做的事情是不可同日而语的。但程序员每天编写的有效代码可能都是50行。每一个语言诞生的第一动力都是:提升在它问题领域的解决问题速度。举例来说:Java在高并发的业务和简单业务代码的处理过于复杂和臃肿,所以Go应运而生,在互联网高并发的业务场景里与k8s结合大行其道。
一个特殊领域内的DSL语言,收缩到其领域可以使用极为简短精炼的语句描述GPL:
# 如下是活动技能A,活动技能B绑定的DSL代码。
bind(skillA,skillB).config(configExcel);
那需要哪些知识才可以构造DSL?可能是很多人想问的问题?我列举了一下,希望大家不要望而却步,这些理论是通向这个目标,必须要面对的问题,逃避不了,我会尽量用一俩句话说描述清楚,每个知识点都在哪个阶段产生的作用,各位需要课下去恶补。
如下是本次讲解案例的流程:

本文为了节省篇幅暂且省略了语法检测,语法编译生成 过程。
| 知识点 | 场景 | 推荐阅读 |
|---|---|---|
| 状态机理论 | 词法分析 | 《Vue.js设计与实现》,《编译系统透视》 |
| 正则表达式 | 词法分析 | 《精通正则表达式》 |
| 巴科斯范式 | 语法分析 | 《Vue.js设计与实现》 |
| AST语法树的生成与遍历 | 代码执行 | 《程序设计语言与编译(第3版)》,《Vue.js设计与实现》 |
| 作用域设计 | 代码执行 | 《编译系统透视》 |
| 扩展性设计 | 扩展性策略 | 《编程之魂》,《松本行弘的程序世界》 |
DSL对比
我目前遇到的有俩种,有同学知道其他的可以补充一下
- 第一种,翻译型,比如vue,react均属于这种,这种特点是,它只需要将自身翻译为目标语言(vue->javascript),剩下的就是目标语言自己的事情了。
- 第二种,编译型,比如java,c++均属于这种,这种特点是,它的需要自己完成代码的解释执行,优化判定等一些逻辑。
本文的实现属于第二种。鄙人一点小观点是对性能极致要求且有能力的同学尽量选择第二种,第一种其实受限于目标语言的实现机理导致一些方面的优化都是束手无策的状态。
案例演示
下图是使用我自己定义的名称为WLang的脚本语言实现的闭包能力的代码。图1 是代码,图2 是执行结果。这个demo展现了目前我现在构造的的DSL所具备的能力
- 图灵完备。
- 支持多种类型数据类型:int,string,以及Map结构。
- 具备闭包能力支持。
- 有日志输出能力。
- 具备注释能力。
# 一个演示案例
var a = 1;
var b = 5;
var c = 8.0;
var d = { aaa:1,bbb:2 };
def testFunc(a1,b1,c1,d1){
var iv = 1 ;
if(iv == 1) {}
var innerFunc = def testFuncIn(){
iv = iv+1+d1.aaa;
return iv;
}
return innerFunc;
}
var innerFunc = testFunc(a,b,c,d);
var r1 = innerFunc();
log "首次闭包调用结果为:"+r1;
var r2 = innerFunc();
log "2次闭包调用结果为:"+r2;
var innerFunc2 = testFunc(a,b,c,d);
var r3 = innerFunc2();
log "3次闭包调用结果为:"+r3;

状态机
状态机在语法是BNF等语法解析的基础,比如我提一个问题大家思考一下(可能不太恰当):
let leta = 1;
计算机是如何知道,第一个let是类型,而第二个let是变量名称的一部分的?计算机在形成语法树的过程中,必须要把各个元素做正确的标记,类定义,接口定义,对象创建,方法调用,才可以做具体的逻辑。这里就是状态机在起作用,大家后面系统学习一下其中有多种理论分支:确定有限状态自动机(DFA),非确定有限状态自动机(NFA),这里就用有限状态自动机(DFA)给大家做演示讲解什么是?
有限状态机(DFA)
计算理论中有限状态机的定义:
有限状态机是一个五元组 (Q, Σ ,δ, q0, F):
Q 是一个有穷集合,叫 状态集
Σ 是一个有穷集合,叫 字母表
δ : Q × Σ → Q 是 转移函数
q0 ∈ Q 是 起始状态.
F ⊆ Q是 接受状态

比如,下面这张图是《编译系统透视》中的一张图,可以看到他这里是和正则表达式结合起来使用了,状态之间的转化依赖与正则表达式,比如。如果下一个输入字符匹配正则 /a-z/,则走第1个逻辑分支。如果下一个输入字符是”数字“,则走第2个个逻辑分支,以此类推,每一次匹配到最后那个“俩层圆圈”的状态为终止,然后周而复始进行下一次匹配。每次匹配生成一个Token。把所有的代码(输入字符)匹配完毕之后,会生成一批有效的Token。这就叫”词法分析“,这个过程会将无效字符丢弃,有效字符合并或者转义。

推荐阅读:《编译系统透视》
非确定有限状态自动机(NFA)
NFA中每一个状态对于字母表的每一个符号(如:0/1)可能有多个箭头射出。其不确定性在于,在一个状态下,输入一个符号,可能转移到n个状态,出现了多种状态转移。另外NFA中箭头的标号可以是 ε(空转移,即:未输入任何符号也可转移到另一个状态),而DFA不允许

如上图非确定有限状态自动机,当对q1状态输入1时,可能转移到q2状态或停留在当前状态。
正则表达式简略
这个就不为大家具体解释了,在语法解析字符串提取方面不可或缺的作用。不过很多时候大家可能只是基础用法,在语法领域,正则表达式的使用场景可谓相当复杂,举例来说:
\\s*((//.*)|([0-9]+)|(\"(\\\\\"|\\\\\\\\|\\\\n|[^\"])*\")|[A-Z_a-z][A-Z_a-z0-9]*|==|<=|>=|&&|\\|\\||\\p{Punct})?
\\s*: 匹配任意数量的空白字符(包括空格、制表符、换页符等)。
//.*: 匹配以//开头的单行注释。//后面可以是任意字符。
[0-9]+: 匹配任意数量的数字。
\"(\\\\"|\"\"\"|\\n|[^\"])*\": 匹配以双引号包围的字符串。双引号内的内容可以包含转义的双引号、反斜杠、换行符以及除双引号之外的任何字符。
[A-Z_a-z][A-Z_a-z0-9]*: 匹配由大写字母、下划线和数字组成的标识符(通常为变量名、函数名等)。
==|<=|>=|&&|\|\||\p{Punct}: 匹配以下几种运算符:等于、小于等于、大于等于、与、或以及标点符号。
这是一段词法解析器使用的提取合法字符的正则,就这个案例来说,如果对正则一知半解是写不出来的,正则表达式是状态机的集大成者。其中有俩种状态机:确定有限状态自动机(DFA),非确定有限状态自动机(NFA)核心的区别在于,NFA支持回溯,这里篇幅有限暂不展开讲了,大家感兴趣可以去了解一下。
推荐阅读:《精通正则表达式》
巴科斯范式(BNF)
要构造抽象语法树,语言处理器首先要知道将会接收哪些单词序列(即需要处理怎样的程序),并确定希望构造出怎样的抽象语法树。通常,这些设定由程序设计语言的语法决定。就像,对一篇英文文章的组成进行归纳,一篇英文文章由段落构成,一个段落有若干句子构成,而一个句子由主谓宾构成,由此概括出英文语法最底层的逻辑结构:一个句子的组成:“主语-谓语动词-宾语”,同理对日语进行分析,最终日语的最底层逻辑为:一个句子的组成“主语-宾语-谓语动词”。
而在计算机语言中用来描述这一规律的工具,就叫巴科斯范式
BNF(Backus-Naur Form)巴克斯范式,在计算机科学领域,BNF 是一种适用于上下文无关的语法的符号表述,常用于描述计算编程语言的语法(文法)、文档格式、指令集以及通信协议等,总之它适用于需要准确描述的地方,如果不用这个东西,我们几乎没办法准确而简洁的表述像计算机编程语言这样需要精准表达的东西。
巴科斯范式Backus-Naur Form,巴科斯范式)-描述语言的语法,是yacc框架直接支持的语法。类似的Antlr框架支持的语法也是BNF范式的变种
factor: NUMBER | "(" expression ")"
term: factor { ("*" | "/") factor }
expression: term { ("+" | "-") term }
如下是同等含义的铁路图表达
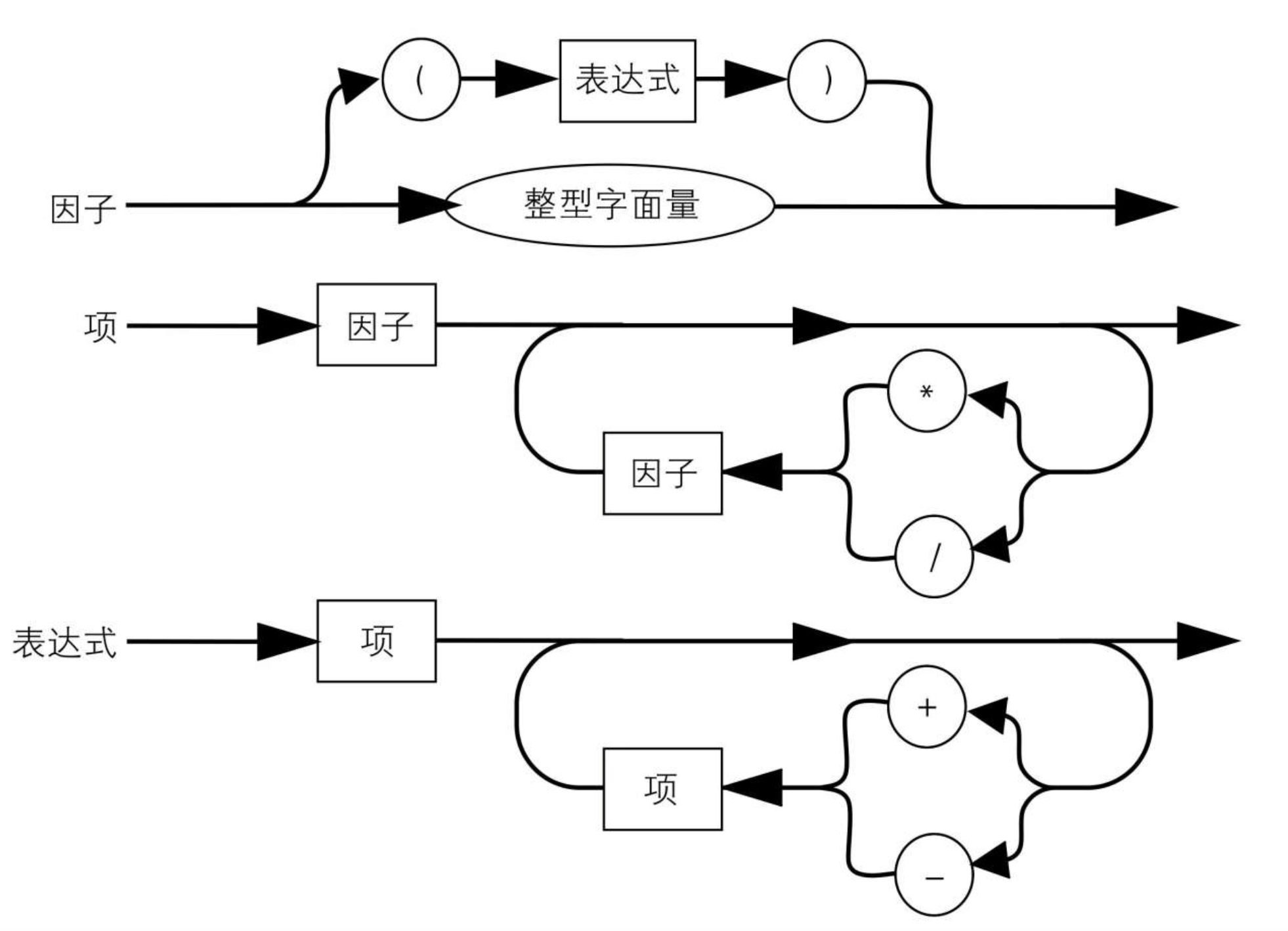
推荐阅读:《程序设计语言与编译(第3版)》
AST语法树的生成与遍历简略
语法树的构建就是基于状态机将代码(输入字符串)解析为BNF所表述的语法结构,当然其中会有一些优先级处理比如 1+25,会被解析为1+(25),这里暂不展开,理论有些复杂,感兴趣的同学我推荐阅读
递归下降分析法
语法树的生成思路大概有俩个思路:自上而下语法分析,自下而上语法分析。这里拿自上而下语法分析介绍一下,另一个由于篇幅原因大家可能需要自己去看一下,其中自上而下分析中比较常见的是递归下降分析法,这是大多数编程语言使用的,递归下降分析法,我用一句话概括一下,利用递归的特性而生成的抽象语法书。
递归说白了就是自己调用自己,或者某一批函数调用自身范围内的函数达到我们调用我们自己的目的,举例如下。
func(a,b){
var val1 = func(a+1,b+1);
var val2 = func(a-1,b-1);
return val1+val2;
}
// 调用函数
func(10,20);
不知道大家看出来没有,递归天生具备树结构的特性,内层的调用通过调用栈能够明确知道谁是它的父节点。同理父节点也是如此,”父节点“可以感知到它所有的”子节点“的,有了这个特性就好办了,每个语法分析匹配的时候,一个生成式对应一个函数,根据生成式的结构,调用其子生成式的函数,只需要全部调用完成,一个树结构也就形成了。
# 如下是巴克斯范式
E→TE'
E'→+TE'|ε
T→FT'
T'→*FT'|ε
F→(E)|i
# 如下是部分函数
def E() {
T();
E'();
}
def E'(){
if(sym =='+')
{
advance();
T();
E'();
}
}

语法树遍历
遍历AST的方式主要有深度优先遍历(Depth-First Search,DFS)和广度优先遍历(Breadth-First Search,BFS)。
- 深度优先遍历(DFS):先访问一个节点,然后递归地访问它的子节点。
- 广度优先遍历(BFS):先访问一个节点的所有子节点,然后再访问该节点的其他子节点。
主要讲解一下深度优先:
主要思路是从图中一个未访问的顶点 V 开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底...,不断递归重复此过程,直到所有的顶点都遍历完成,它的特点是不撞南墙不回头,先走完一条路,再换一条路继续走 ,还需要细分:前序遍历,还是中序遍历,后序遍历。
一般的语法树遍历都使用的深度优先遍历前序遍历。
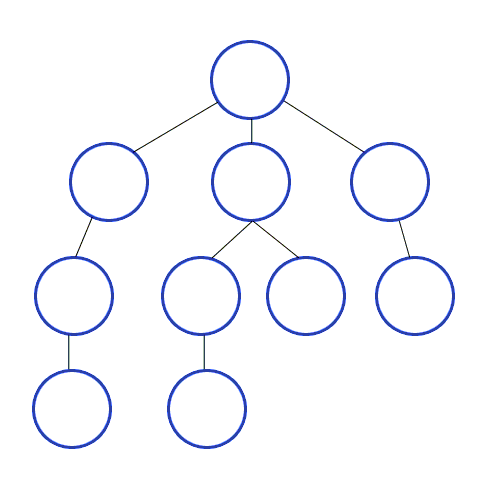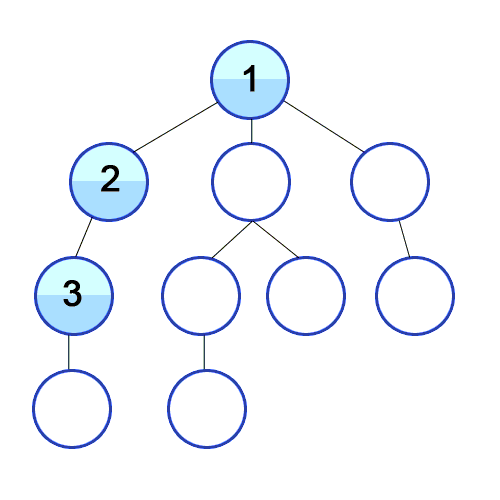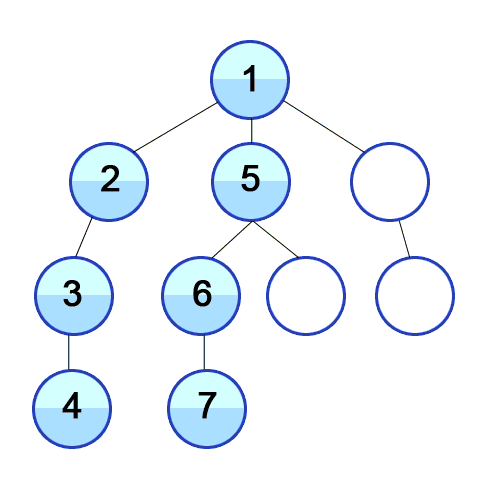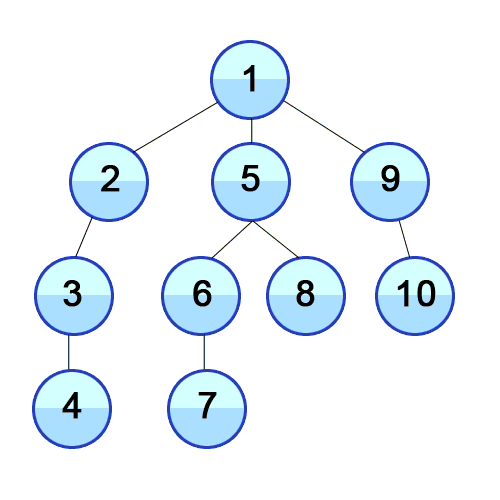
框架支持
语法树支持框架:yacc,ANTLR和JavaCC,它们都提供了遍历和访问AST的API。
当然也可以自己实现,前面已经讲了状态机,这里也讲了自顶而下,深度优先,我们其实已经具备自己实现的理论基础了,嘿嘿,那些框架也就做了这些事情。
我是基于Antlr框架落地的DSL,基于Antlr框架的,它直接帮助生成Listener或者Visitor等等相应的工具类,方便一些。
看到这大家肯定心里打鼓,早把框架抛出来不就行了,讲那么多理论干什么?我要提醒:框架只帮我们做了很薄的一层语法树遍历的操作,且默认使用深度优先的方式来遍历,如果不了解前面的知识点,是不知道某个具体的回调点在哪种时机调用,从而我们可以做合适的事情,比如创建或者清除作用域。
推荐阅读:《程序设计语言与编译(第3版)》《Antlr4权威指南》
作用域设计
大家看一下如下代码,思考一下,这段代码中d()函数的调用的运行涉及到了几个作用域?
var a = 1 ;
var b = func(var c,var d){
int f = c+d;
return func(){ return f };
}
var d = func(a+1,3+2);
d();
答案是3个,各位有没有答对 1.调用d函数的环境(全局环境),2.定义函数d时的环境,3.d函数执行时候的内部环境。所以到现在为止我们要解决的问题就明确了,要实现这三套环境和正确管理环境间关系那么环境间的关系是怎样的?如上3个环境,我把三个环境分别定义为,A(调用d函数的环境),B(定义函数d时的环境),C(d函数执行时的内部环境)
- 环境A:其中这句代码中 func(a+1,3+2);:a+1,3+2 的执行在环境A中执行。
- 环境A->环境B:a+1,3+2 执行完成之后,将执行结果赋值给func(var c,var d){} 函数变量c,和d,此时执行环境从环境A转移到环境B。
- 环境B->环境A:环境B执行return func();此时func将被传递给环境A的d变量,此时执行环境从环境B迁移到环境A
由此完成了环境之间的数据扭转。
据此有如下实现思路:
- 使用深度优先遍历AST语法树,同时使用Map容器对作用域进行管理:mainEnv维护全局环境,runTimeEnvStack维护当前环境堆栈。
- 在遍历到函数定义语句时,使用Function对象,记录当前调用环境,为定义环境。
- 在遍历到函数调用语句时,从当前环境中获取上次保留的Function对象,从Function对象中获取定义环境,作为当前环境的父环境,开始函数执行。
尤其是第2,2步,是实现闭包至关重要的步骤。
// 函数定义语句处理
public Value visitFuncDefExpr(WlangParser.FuncDefExprContext ctx) {
// 获取当前环境
Environment currenrEnv = EnvUtil.getCurrentEnv(mainEnv,runTimeEnvStack);
// 创建Function对象将Function作为Val,put入当前调用环境
Function function = new Function(currenrEnv,ctx);
Value funcVal = new Value(function);
String funcName = ctx.ID().getText();
currenrEnv.put(funcName,funcVal);
return Value.VOID;
}
// 函数语句调用
@Override
public Value visitFuncCall(WlangParser.FuncCallContext ctx) {
Environment callEnv = EnvUtil.getCurrentEnv(mainEnv,runTimeEnvStack);
String id = ctx.ID().getText();
Value funcVal = (Value)callEnv.get(id);
// 等等一些判断语句 ...
// 获取具体的function对象
Function function = (Function)funcVal.getValue();
// 使用function语句定义的环境为父,生成新内部环境。
Environment funcNewEnv = ((Function)funcVal.getValue()).makeEnv();
... 调用函数
}
大家可以思考一下,我们的作用域还有哪些优化空间?这作为我们下一个课题的内容了,嘿嘿。
推荐阅读:《编译系统透视》《程序设计语言与编译(第3版)》,《松本行弘编程语言的设计与实现》
语法树解析
var a = 1;
var b = 5;
var c = 8.0;
def testFunc(a1,b1,c1){
return (a1+b1+c1);
}
var resultVal = testFunc(a,b,c);
log "结果为:"+resultVal;

图1,图2,分别是源代码以及它对应的语法树,并且以深度优先遍历的方式,我用红线标出了顺序,调用遍历次序就是标记的记号,其中每次遍历到具体的节点都会触发具体相应的回调函数。
比如这是ValDefExpr节点被遍历到时候触发的回调函数,看得出来这是“定义语句”,做了赋值的操作,且有一个重点,当回调到该节点之后,该节点并没有继续使用深度优先遍历去遍历其子节点。而是一部分遍历了“this.visit(ctx.expr());”所以具体的语法解析,并不是只是单纯的采用深度优先遍历,而是深度优先+特殊语义节点定制化处理。
## 第一个案例是赋值语句的解析 案例:var a = 1+2;
@Override
public Value visitValDefExpr(WlangParser.ValDefExprContext ctx) {
// 获取当前作用域
Environment currenrEnv = EnvUtil.getCurrentEnv(mainEnv,runTimeEnvStack);
if(ctx.definitionFront2()!=null && ctx.definitionFront2().ID()!=null){
// 获取定义语句的变量名称 a
String id = ctx.definitionFront2().ID().getText();
Value valObj = null;
// 如果存在赋值语句,则计算1+2
if(ctx.expr()!=null){
valObj = this.visit(ctx.expr());
}
// 将计算结果以a为key 计算结果为val,放入作用域。
currenrEnv.put(id,valObj);
}
return Value.VOID;
}
## 第二个案例是 if语句的解析 案例:if(a>1){a=1;}else if(a>2){a=2;}else{a=3;}
@Override
public Value visitIfStat(WlangParser.IfStatContext ctx) {
List<WlangParser.ConditionBlockContext> conditions = ctx.conditionBlock();
boolean evaluatedBlock = false;
for(WlangParser.ConditionBlockContext condition : conditions) {
// 执行if判断语句代码块 比如 if (a>1) 对应a>1 部分
Value evaluated = this.visit(condition.expr());
// 如果满足if条件,则执行包裹代码块 if(a>1){a=1;} 对应的{a=1;} 部分
// else if 以此类推
if(evaluated.asBoolean()) {
evaluatedBlock = true;
// 执行代码块
this.visit(condition.statBlock());
break;
}
}
// 执行else代码块,所有elseIf 语句都没有被执行,且有else语句代码块定义,则执行else语句包裹的代码块
if(!evaluatedBlock && ctx.statBlock() != null) {
this.visit(ctx.statBlock());
}
return Value.VOID;
}
大家可以感受一下,我所说的特殊语义节点定制化处理了么,在语法树遍历到赋值语句,if语句之后,通过回调函数的方式把遍历的选择权交给了我,然后我在回调内部进行具体的定制化遍历逻辑,依据不同语句的特性和处理结构。
依次需要处理的语义节点如下:
stat
:assignment # 赋值语句
|definition # 定义语句
|funcCall # 函数调用语句
|ifStat # if语句
|whileStat # while语句
|log # 日志输出语句
|OTHER {System.err.println("未知异常: " + $OTHER.text);}
且有一个规律,父节点对子节点是全局视角,子节点的文本信息,遍历后的返回值,父节点是全部可以感知到的。所以举例这句代码来说:
var a = 1+2*3;
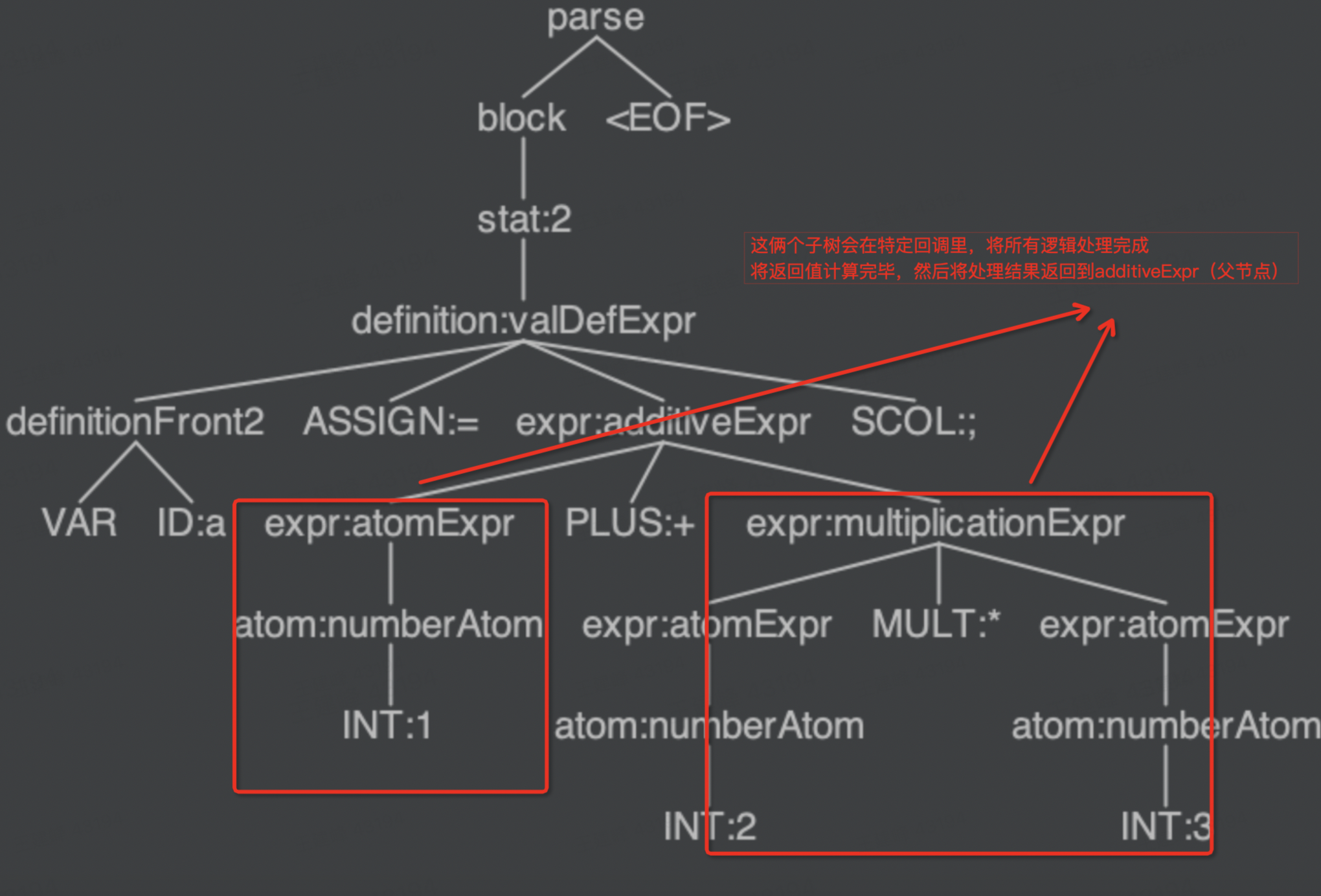
这个就是代码执行的基本原理,不过有优化空间的,大家不妨思考一下,这种语法树遍历有什么问题?
下一期预告
在上面的内容中也提到了我们目前只做到了执行源代码,还有可以优化空间的。
- 作用域的数据结构使用Map形式,效率低下,该如何优化?
- 代码执行一次需要完整的遍历AST,效率低下,该如何优化?
- 每次代码执行的过程中,一些代码其实可以提前计算好比如"var = 1;",该如何优化?
以上三点作为我下一次的主题。