从一个实际AI项目看,AI应用开发需要学什么?
引言
作为一个Java开发人员,如何上手AI开发应用,这应该是大多数同学的困惑,本文使用一个实际的AI应用出发,分析其实现技术,从而给出学习路径。给大家解惑:我该如何学,学什么?
一个AI项目分析
AI应用榜单:https://www.aicpb.com/
国内AI应用榜单热评榜|2025年第12周** 第二名
AI项目功能分析
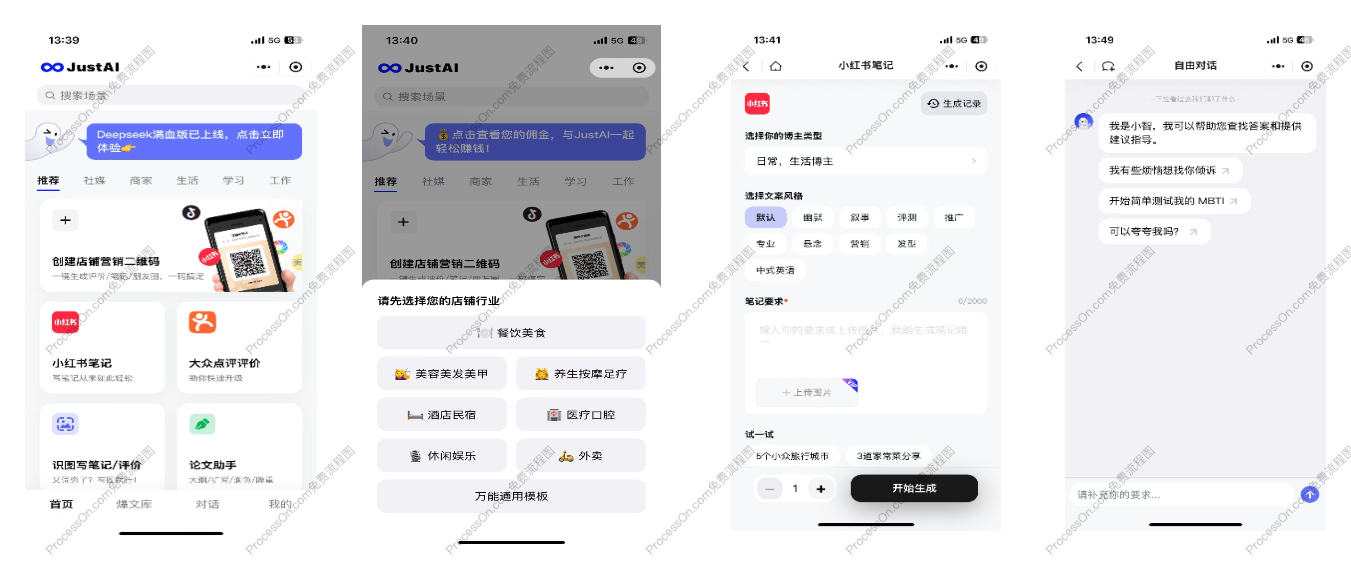 !
!
这是一个针对对运营各个文案场景的AI应用。用于互联网运营工作。其中维护了各种Agent实现,针对运营人员,在小红书,大众点评等等平台,发帖子的行为。仿写别人文章的行为,洗稿。
AI项目技术能力分析
- 爬虫 - 定期爬取小红书等网站的内容。
- AI 分类 - 将爬取完成的内容AI进行有限归类。
- OCR:图片信息提取。
- 多模态:文生图。
- 多Agent:仿写Agent,客服Agent,各业务Agent。
- 结构化输出:大模型输出格式结构化成Bean。
总结 :除了几个基座模型应用(ChatGpt,DeepSeek,豆包)其他的大模型应用,基本都是以优秀的交互体验取胜。技术不是核心壁垒。(所有的AI应用基本都是,RAG,多模态应用,智能体,工作流,MCP,这几类为主。)
当前市面技术分析
AI 开发框架:Langchain,Spring AI,langchain4j,Spring AI Alibaba。
基本都集成了基础功能:Agent,工作流,Function Calling,MCP协议 等基础能力。
对比总结
| 框架 | 语言/生态 | 核心优势 | 适用场景 | 局限性 |
|---|---|---|---|---|
| LangChain | Python | 社区活跃,功能全面,多模态支持 | 快速原型开发,复杂NLP任务 | 依赖Python生态,企业级支持较弱 |
| LangChain4j | Java | 标准化API,Spring集成,高性能 | 企业级Java应用,RAG系统 | 部分功能尚在开发中 |
| Spring AI | Java/Spring | Spring生态兼容,企业级特性丰富 | 现有Spring项目AI扩展 | 依赖Spring框架 |
| Spring AI Alibaba | Java/阿里云 | 阿里云服务深度集成(推测) | 阿里云生态的中文AI应用(需验证) | Spring AI 二次开发 |
结论:选择Spring AI Alibaba,这是阿里基于Spring AI同时集成自身的云服务(百炼平台)形成了二次开发框架:Spring AI Alibaba(https://java2ai.com/),上手门槛较低,且有国内技术团队迭代维护。是我们主要选择的技术框架。
学习建议
第一步,先将Spring webflux概念学习一遍,对流应用开发有基本的了解。
第二步,langchain4j,Spring AI Alibaba ,Spring AI,的各个demo和文档看一遍,对一些基础概念心中有数。
第三步,在扣子上查看一些排名较高的工作流应用,Agent,尝试使用代码实现。
第四步,Prompt 提示词编写与维护学习(优秀的提示词可以最大化节点能力)。
基础概念学习:可以LangChain4j的源码和demo为主去学基础概念,使用Spring AI 的源码和样例辅助
LangChain4j 基本是照抄Langchain的设计,而现在AI应用开发中很多概念都是LangChain先提出。
基于JustAI的样例实现
如下案例基于如上JustAI应用,需要使用的能力,编写的代码demo,将如下能力实现,就可以做到JustAI的所有能力。
归根就是用产品设计,将如下能力组合提供。
基础概念:LLM,工具(Function Calling),Memory,Prompt,格式化输出(Structured Output),智能体,多模态。
LLM:大模型基座,一般选择俩个以上的API基座,互相补充,或者特殊场景的调优,比如阿里有专业的金融大模型。
工具(Function Calling) :工具,用于弥补大模型在专业任务上的不足,比如科学计算器,比如天气查询。
Memory :上下文记忆,一般为20轮次对话
其他Agent基础概念 :https://docs.spring.io/spring-ai/reference/
如下实现了6个 样例:AI Agent,文生图,结构化,爬虫Tool,仿写工作流,OCR
AI Agent
基于业务场景细分管理不同的Prompt模板。配合交互输出。
如下以 自然语言生成SQL的场景,写一个Agent Demo
样例演示
自然语言生成SQL的Prompt
Given the DDL in the DDL section, write an SQL query to answer the question in the QUESTION section.
Only produce select queries. If the question would result in an insert, update,
or delete, or if the query would alter the DDL in any way, say that the operation
isn't supported. If the question can't be answered, say that the DDL doesn't support
answering that question.
Answer with the raw SQL query only; no markdown or other punctuation that isn't part of the query itself.
QUESTION
{question}
DDL
{ddl}
DDL 语句如下(其实有更简洁的描述):
-- Authors
create table Authors (id int not null auto_increment,firstName varchar(255) not null,lastName varchar(255) not null,
primary key (id));
-- Publishers
create table Publishers (id int not null auto_increment, name varchar(255) not null,
primary key (id)
);
-- Books
create table Books (id int not null auto_increment,isbn varchar(255) not null,title varchar(255) not null,author_ref int not null,publisher_ref int not null,
primary key (id)
);
代码样例如下(JAVA):
@PostMapping(path = "/sql")
public Answer sql(@RequestBody SqlRequest sqlRequest) throws IOException {
String schema = ddlResource.getContentAsString(Charset.defaultCharset());
String query = chatClient.prompt().user(userSpec -> userSpec
.text(sqlPromptTemplateResource)
.param("question", sqlRequest.question())
.param("ddl", schema)
).call().content();
assert query != null;
if (query.toLowerCase().startsWith("select")) {
return new Answer(
query,
jdbcTemplate.queryForList(query)
);
}
throw new SQLGenerationException(query);
}
}
提问:
How many books has Craig Walls written?
返回:
SELECT COUNT(*) FROM Books INNER JOIN Authors ON Books.author_ref = Authors.id WHERE Authors.firstName = 'Craig' AND Authors.lastName = 'Walls'
需学习内容
-
Spring webflux:《Spring in Action》第五版,《Spring 5.0 项目实战》
-
Prompt工程:https://prompt-guide.xiniushu.com/
-
Prompt指南2:https://github.com/PlexPt/awesome-chatgpt-prompts-zh
提示 :可以使用扣子工作流内置的功能,逐个调试Prompt,和大模型效果对比
多模态-文生图
文生图的核心不是一次性生成图片,而是基于当前图片调整的能力。
本Demo 是依赖于阿里云百炼平台的能力。
场景有三个:
- 生成:一句话生成商标。
- 修改:基于当前生成的商标,修改细节,细节优化。
- 缩放:图片缩放(由于大模型生成图片的尺度受限)。
- 保存:将完整的图片保存到云服务和本地。
样例演示
1、生成
@GetMapping("/image")
public void image(HttpServletResponse response) {
ImageResponse imageResponse = imageModel.call(new ImagePrompt("小狗图片"));
String imageUrl = imageResponse.getResult().getOutput().getUrl();
try {
URL url = URI.create(imageUrl).toURL();
InputStream in = url.openStream();
response.setHeader("Content-Type", MediaType.IMAGE_PNG_VALUE);
response.getOutputStream().write(in.readAllBytes());
response.getOutputStream().flush();
} catch (IOException e) {
response.setStatus(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);
}
}
2、修改

// 涂抹+原始图片+提示词 修改图片
private ImageSynthesisParam genImageSynthesis(){
HashMap<String,Object> extraInputMap = new HashMap<>();
extraInputMap.put("base_image_url", "http://synthesis-source.oss-accelerate.aliyuncs.com/lingji/validation/mask2img/demo/source3.jpg");
extraInputMap.put("mask_image_url", "http://synthesis-source.oss-accelerate.aliyuncs.com/lingji/validation/mask2img/demo/glasses.png");
String prompt = "a dog wearing red glasses";
String model = "wanx-x-painting";
return ImageSynthesisParam.builder()
.model(model)
.prompt(prompt)
.n(1)
.size("1024*1024")
.extraInputs(extraInputMap)
.build();
}
3、缩放

调用代码如下
curl --location --request POST 'https://dashscope.aliyuncs.com/api/v1/services/aigc/image2image/out-painting' \
--header 'X-DashScope-Async: enable' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "image-out-painting",
"input": {
"image_url": "https://huarong123.oss-cn-hangzhou.aliyuncs.com/image/%E5%9B%BE%E5%83%8F%E7%94%BB%E9%9D%A2%E6%89%A9%E5%B1%95.png"
},
"parameters":{
"angle":0,
"output_ratio":"4:3",
"best_quality":false,
"limit_image_size":true
}
}'
4、保存
通常生成的最终图片要保存的云存储,或者本地。这一般基于各个家自己实现,阿里云,七牛云都可以
需要学习内容
- Spring AI Alibaba 图生文API()
- 百炼平台(文生图)文档
结构化输出
如下是基于Spring AI 的demo
大模型输出的格式不固定,没法兼容应用程序业务逻辑,所以在特殊的环节上需要使用很多方式将大模型的输出内容转为结构化内容。
- 一种是使用Prompt提要求。
- 大模型输出完成之后二次加工整合。
第一种为主流,响应速度较快(与大模型交互次数较少),使用第一种思路整合
样例演示
Prompt 如下:
requirement: 请用大概 120 字,作者为 王大爷 ,为计算机的发展历史写一首现代诗;
format: 以纯文本输出 json,请不要包含任何多余的文字——包括 markdown 格式;
outputExample: { "title": {title},"author": {author},"date": {date},"content": {content}};
代码样例(JAVA)
@GetMapping("/play")
public StreamToBeanEntity simpleChat(HttpServletResponse response) {
var converter = new BeanOutputConverter<>(new ParameterizedTypeReference<StreamToBeanEntity>() {});
Flux<String> flux = this.chatClient.prompt().user(u -> u.text("""
requirement: 请用大概 120 字,作者为 王大爷 ,为计算机的发展历史写一首现代诗;
format: 以纯文本输出 json,请不要包含任何多余的文字——包括 markdown 格式;
outputExample: {
"title": {title},
"author": {author},
"date": {date},
"content": {content}
};
""")).stream().content();
String result = String.join("\n", Objects.requireNonNull(flux.collectList().block())).replaceAll("\\n", "")
.replaceAll("\\s+", " ")
.replaceAll("\"\\s*:", "\":")
.replaceAll(":\\s*\"", ":\"");
log.info("LLMs 响应的 json 数据为:{}", result);
return converter.convert(result);
}
需学习内容
-
Prompt工程:https://prompt-guide.xiniushu.com/
-
Spring AI结构化输出文档:https://docs.spring.io/spring-ai/reference/api/structured-output-converter.html
大模型爬虫Tool
基于Function Calling 协议 编写爬虫Tool。
如下是基于Spring AI 框架的demo。
定时任务 - 定时爬取小红书,知乎上的内容。
样例演示
1、定义Tool
public interface CrawlerService {
String run(String url);
}
public class CrawlerJinaServiceImpl extends CrawlerService {
@Override
public String run(String targetUrl) {
URL url = URI.create(CrawlerConstants.JINA_BASE_URL).toURL();
Map<String, String> requestParam = Map.of("url", targetUrl);
String requestBody = this.objectMapper.writeValueAsString(requestParam);
logger.debug("Jina request body: {}", requestBody);
HttpURLConnection connection = this.initHttpURLConnection(jinaProperties.getToken(), url, this.getOptions(),
requestBody);
return objectMapper.writeValueAsString(this.convert2Response(this.getResponse(connection)));
}
}
2、注册Tool
@Configuration
@EnableConfigurationProperties({ CrawlerJinaProperties.class })
@ConditionalOnProperty(prefix = CrawlerJinaProperties.JINA_PROPERTIES_PREFIX, name = "enabled", havingValue = "true")
public class CrawlerAutoConfiguration {
@Bean
@ConditionalOnMissingBean
@Description("web Reader Service Plugin.")
public CrawlerJinaServiceImpl jinaFunction(CrawlerJinaProperties jinaProperties, ObjectMapper objectMapper) {
Assert.notNull(jinaProperties, "Jina reader api token must not be empty");
return new CrawlerJinaServiceImpl(jinaProperties, objectMapper);
}
}
3、大模型使用Tool
/**
* 调用工具 - function
*/
@GetMapping("/chat-tool-function")
public String chatTranslateFunction(@RequestParam(value = "query", defaultValue = "查看一下这个网页:www.baidu.com") String query) {
return dashScopeChatClient.prompt(query).tools("jinaFunction").call().content();
}
在大模型使用的时候,它会基于 @Description("web Reader Service Plugin.") 注解,和提问,自动判断是否需要使用工具,使用什么工具。
可以使用现有的 Java爬虫框架:gecco,webCollector. 封装为Tool 供其调用
需学习内容
Spring AI Tools文档:https://docs.spring.io/spring-ai/reference/api/tools-migration.html
仿写工作流
基于当前热门的小红书文章,洗稿,基于要求生成一篇文章
样例演示
工作流程如下:
- 爬虫获取数据(参见爬虫Tools实现):小红书,知乎,美团等等数据。
- 选择风格,要求(用户交互)(选择风格Promt)
- 节点1(LLM) - 原文内容提取(移除掉干扰项,将图片清除,表情清除)
- 节点2 (LLM)- 完成对目标文章切割按照大纲切割
- 节点4 (LLM)- {大纲 - 部分} +{部分原文} 生成部分+{ 用户要求 }。(循环)
- 节点5 (逻辑)- 将生成的各个部分组合为一篇整体的文稿。
实际工作流如下:
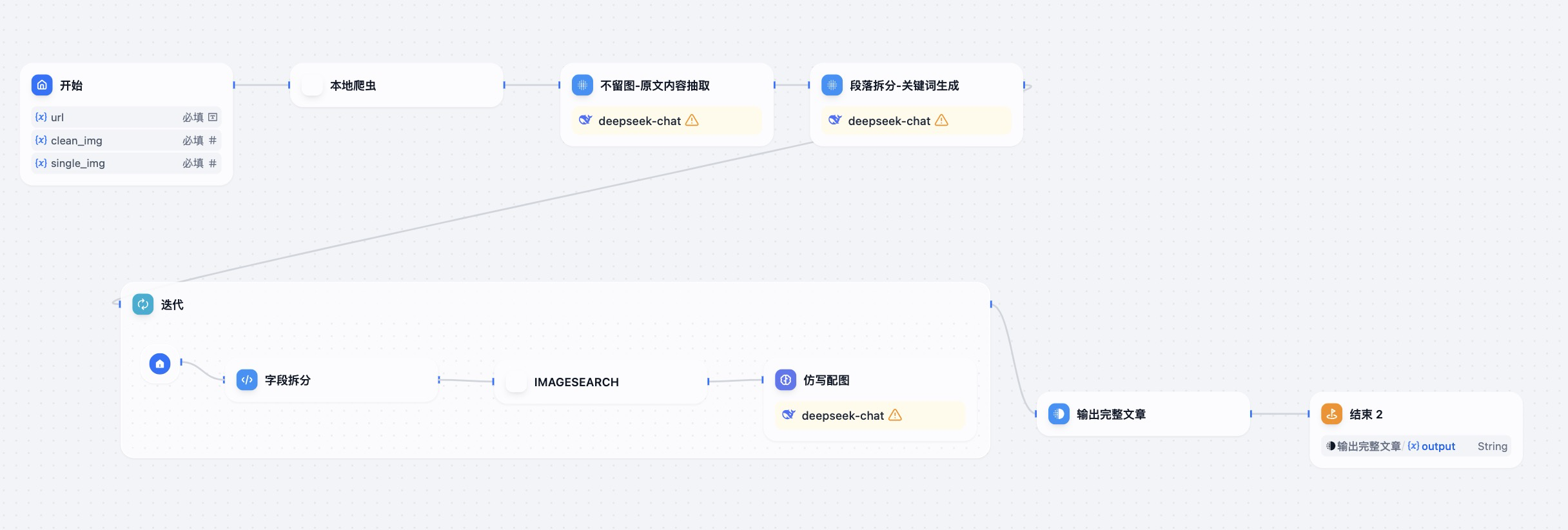
如下列出几个核心节点的逻辑:
1、节点1
原文内容抽取Prompt
请对以下网页内容进行清洗,并抽取网页中的文章内容信息。请避免包含文章内容无关的信息,例如:html标签、页头、页尾。请对清洗后的信息进行markdown的格式输出。
### 约束条件
1.文本信息中如果有明显的标题信息请直接抽取,不需要自定义生成或加工
2.文本的正文内容请尊重原本描述抽取,不需要自定义生成或加工
3.关键词将用作图片多模态检索,请不要包含无意义的词组或短语。
4.请完整抽取原文内容,并保持段落排版
5.请过滤版权信息、编辑、作者、来源、转载以及与原文内容无关的信息
### 抓取内容如下:
```
{{#1718967141318.text#}}
```
2、节点2
完成对目标文章切割按照大纲切割
请分析文章的内容结构,将文本划分为一个或多个语义完整的章节,每个章节不少于400字。并为每个章节生成若干个用于检索图片的关键词或描述,多个关键词使用逗号进行分割。输出结构为json
Example:{
"sections": [
{
”keywords“: ”关键词或描述字符串“,
”section“: "章节内容1"
},
{
”keywords“: ”关键词或描述字符串“,
”section“: "章节内容2"
},
{
”keywords“: ”关键词或描述字符串“,
”section“: "章节内容2"
}
]
}
3、节点3(循环体)
该节点用于分段仿写
你是一位专业的文字工作者,你可以胜任各种领域的文章仿写,请你对以下提供的参考文章进行仿写并排版。
### 约束条件
1.请确保生成的文章符合编辑规范,不要包含明显的标题、正文、结论等字眼
2.请分析该段落是否需要配图,如果需要请输出仿写后的段落后接配图信息,如果是单段落请将配图放置余段落前,配图信息只需要输出markdown格式的图片
3.请尽可能遵循文本描述的客观事实信息,不要胡编乱造
4.请遵循文本内容的写作风格和用词,输出的段落请尽量确保行文通顺自然
5.请确认排版信息符合markdown规范。
6.请不要添加文章以外的多余信息,如落款、出处、来源、发布时间、作者、编辑等。
### 参考文章内容:
- 标题:{{#17190400701430.title#}}
- 图片:{{#1719052020538.text#}}
- 是否单段落:{{#1719062922068.single_section#}}
- 内容:{{#1719051705186.section#}}
需学习内容
- 可视化工作流 - coze.cn
- 编码工作流(Spring AI Alibaba Graph)
- Prompt工程:https://prompt-guide.xiniushu.com/
OCR文字识别
在java中可以使用框架Tess4J,做OCR识别
也可以使用通义大模型qwen-vl-ocr专门用于图转文,提取信息比较精确。
在JAVA中可以使用框架Tess4J,做OCR识别。
<!-- Tess4J依赖 -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.4.0</version>
</dependency>
样例演示
1、代码实现
// 执行OCR识别
private void execute(BufferedImage targetImage) {
File file = new File(tempImage);
ITesseract instance = new Tesseract();
// 设置语言库位置
instance.setDatapath("src/main/resources/data");
// 设置语言
instance.setLanguage(language);
Thread thread = new Thread() {
public void run() {
String result = null;
try {
result = instance.doOCR(file);
} catch (Exception e) {
e.printStackTrace();
}
resultArea.setText(result);
}
};
ProgressBar.show(this, thread, "图片正在识别中,请稍后...", "执行结束", "取消");
}
2、测试结果:

十 年 生 死 两 茫 茫 。 不 思 量 , 自 难 忘 。
干 里 孤 坟 , 无 处 话 凄 凉 。 纵 使 相 逢 应 不 识 , 尘 满 面 , 鬓 如 霜 。
夜 来 幽 梦 忽 还 乡 。 小 轩 窗 , 正 梳 妆 。
相 顾 无 言 , 惟 有 泪 十 行 。 料 得 年 年 肠 断 处 , 明 月 夜 , 短 松 岗 。
需学习内容
- Java框架-tess4j 的使用
深入研究
深入研究一般细分三个方向:RAG应用,MCP应用,垂直模型训练。如下整理了一些学习资料。
| 类型 | 名称/描述 | 链接 |
|---|---|---|
| Prompt工程 | 提示词工程指南(xiniushu) | 链接 |
| Prompt工程实践指南 | 链接 | |
| Awesome-Prompt,awesome-chatgpt-prompts-zh(github) | 链接 | |
| 模型训练 | OpenAI官方微调指南 | 链接 |
| LLaMA-Factory(开源微调工具库) | 链接 | |
| LLM Agent | LLM Agent论文合集(GitHub仓库) | 链接 |
| **** | 什么是MCP? | 链接 |
| Spring AI 使用MCP客户端文档 | 链接 | |
| Spring AI实现检索增强生成(RAG)文档 | 链接 | |
| 基础理论 | 《深度学习》(花书) | 书籍(无公开链接) |
| 《Python机器学习实战》 | 书籍(无公开链接) | |
| Transformer 论文《Attention Is All You Need》 | arXiv链接 | |
| 向量数据库 | Milvus官方文档 | 链接 |
| 向量数据库学习指南(第三方教程) | [链接]( |